Blog
Implementation of the Data Contracts with dbt, Google Cloud & Great Expectations - Part 1
Reading time.
1 min
Wrtitten by
Astrafy
Analytics Engineering
Data Quality

“Data contracts are like bridges, connecting disparate islands of information; their strength lies not in their existence, but in their precision, clarity, and mutual understanding.”
Introduction
In our contemporary, data-driven business environment, the discipline of data management is continually evolving, and organizations are actively seeking ways to improve the integrity, availability, and reliability of their data. In this context, the ‘data contracts’ concept emerges as a powerful tool. Data Contract is an agreement between Data Producer and Data Consumer regarding the data provided. It can refer to various features of the data like schema, values contained in the data, or the timeliness of it. This series explores how data contracts can be implemented using Data Build Tool (dbt), Google Cloud, and Great Expectations.
This series is split into three parts:
Part 1 provides a high-level overview of Data Contracts subsystems and a gentle introduction to all of the technologies that will be used throughout this series.
Part 2 focuses on the implementation of the Data Contract repository and how Data Producers and Consumers collaborate to make sure the data is of the highest quality.
Part 3 features an in-depth look at executing Data Contract checks in runtime and explores their outcomes.
Data Contracts stand on top of various technology stacks and architectures developed in the last years. This means that talking about Data Contracts inevitably brings in a lot of new concepts and frameworks. In the later part of the article, you can find the Glossary of the terms used with links for further exploration of the concepts.
This series will focus on Data Contracts that are external to any one system and can be extended with additional functionality depending on the needs of your organization. It is another iteration of the data contract system, therefore a lot of the infrastructure components you may find familiar if you have already read our previous article about Data Contracts. It describes in detail some of the aspects that will be covered here only briefly so make sure to take a look!
High-Level Architecture of the Data Contract System
Data Contracts are being fleshed out in the industry and there are different approaches to building a system using Data Contracts. No matter the details though, from a high-level viewpoint, any system capable of performing Data Contracts work will need two parts:
Data Contracts Management Layer
Data Contracts Execution Layer
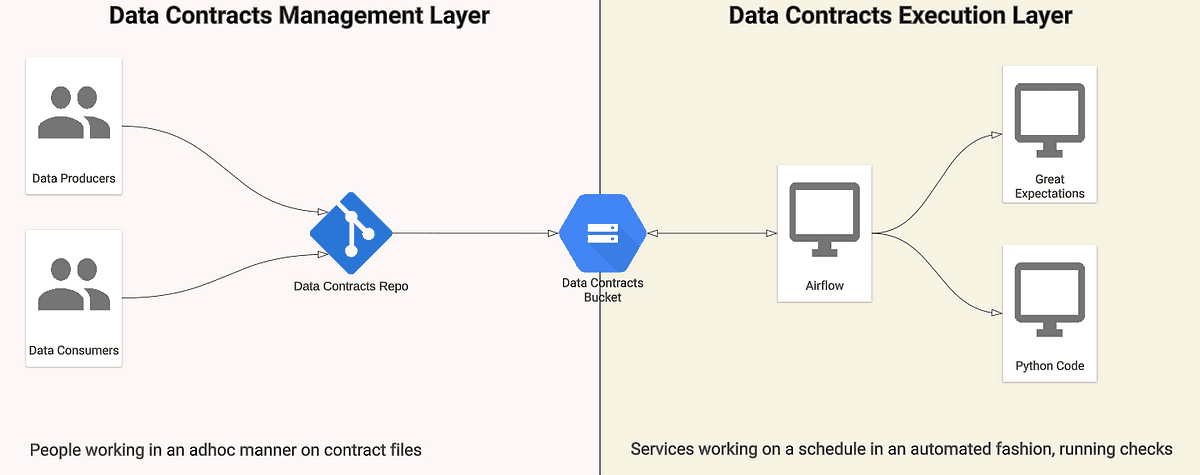
Data Contracts Management Layer
This part of the system allows Data Producers and Data Consumers to collaborate in creating and maintaining the data contracts. The key part of this layer is Data Contract Store. This is the place where Data Contracts will be kept and versioned to allow for lookup when needed. On top of the storage, Data Producers need the ability to propose changes to data contracts and Data Consumers need the ability to comment and accept the changes. For Astrafy implementation we’ve chosen a combination of git repository and a Cloud Storage bucket. As a Google Cloud partner we are always favouring Google Cloud products.
Contracts are after all text files, that need to be read, written, and understood by humans. They usually contain some sort of schema that describes the columns. When Data Producers want to introduce the change to the contract, they edit the file, commit the changes and push it to the git repository. They then open PR and request a review from Data Consumers. This ensures that Consumers acknowledge the change. They can also interfere by adding comments and learn more about the change from Producers. The git repository does not allow merging of the PRs without the explicit approval of Data Consumers. This enforcement is one of the purposes of a “contract” where one party cannot change unilaterally the definition of the contract.
After the merge happens CI pipeline is triggered which bumps the latest git tag and then deploys a new set of contracts under a new version to the Cloud Storage bucket. There, each version is a separate directory, so that you can always roll back to the earlier versions of the contract. On top of that, you can leverage the retention policies and permanently lock the bucket with the contracts so that no bad actor can modify the files directly, although for most cases simple IAM roles management should be enough to keep only the dedicated personas available to modify the bucket contents.

Note that this implementation has all data contracts in a single repository. This has the advantages of being easy to set up, and when introducing structural changes to contracts (like adding new meta attributes) it is more simple to upgrade all of it in one place. However, when dealing with large data organizations, having all of the contracts in one place can also slow down the changes, when multiple parties need to commit to the repo frequently. For such cases you can consider having one contract repository per data product.
Data Contracts Execution Layer
This part deals with running the checks that are engraved in the data contract. Usually, data is processed in a batch mode, on a schedule, most commonly every day. This means that every day new chunk of data with values regarding the last day is being processed and appended to the table. Data producers, sometimes unknowingly can introduce changes from day to day. This might cause failure downstream when Data Consumers are trying to read the data. Therefore the data contract aims to run the checks and if any of them fail, abort the scheduled transformations (they would fail or produce bad-quality data anyway) and alert producers.
This step should happen immediately before the data transformation. For this implementation, we used a standard data processing stack, which is dbt on BigQuery scheduled by the Airflow instance. Therefore execution of data contract checks needs to happen as a separate task in Airflow’s DAG. This gives us the benefit of an easy transformation skip, when the data contract stage fails — by default, Airflow will not execute a downstream task if any of the upstream ones have failed.
Data Contracts can encode a variety of information and checks that can be done against a given table, as depicted in following diagram:

In this implementation, we will focus on schema validation. We want to make sure that fields that are in the contract schema, are present in the actual table schema that we will attempt to read. We will check both the name and the type of the fields, to make sure the schema is valid. Note that, our goal here is to make sure that the fields that are needed for the Consumers are present, not that table has no other columns than the contracted ones. This way, Consumers can rely on the data safely thanks to the contract, but also Producers are free to extend table functionality and add more fields, without modifying the contract every time.
Let’s emphasize this point here. Both Consumers and Producers are the groups that are in the organization and we care about the wellbeing of both of them. Data contracts are a mean to help with data quality, but they cannot be too much of a burden for the Producers so they will seek alternative solutions to producing the data. The spirit of collaboration between Producers and Consumers is crucial for any Data Contract System to work.
Since our Airflow has separate DAGs for each Data Product, data contracts will also be run “per data product”. This means that our execution logic needs to know what contracts should be run for a given data product and also, for any given contract what is the fully qualified table id. Our implementation solves the first issue by keeping the contracts in a directory with the name of the data product. For the second point, we maintain a mapping table between the name of the table in the data contracts repository and the table id in BigQuery. More information about this implementation as well as the alternatives can be found in part three.
The schema validation step could be just Python code, but we opted for wrapping it in Great Expectations. Not only is it an extensible tool providing an astounding amount of checks from the ‘get-go’, but also it provides a GX Cloud interface that serves as a web monitoring tool that is easy to access and navigate for all the people involved.
Lastly, we wrap Great Expectations code in a Docker container and we run it with Kubernetes Pod Operator on Airflow. This way the Airflow concerns itself only with the scheduling and the runtime layer and all the dependencies needed for the execution are prepared in a separate process of building an image.
When Data Contract validation fails, the alert is sent. Depending on the tools used in your organization it can be a message to a channel on Slack or Teams or a serious alert in Pager Duty. This is also handled by the custom Python logic in the Docker container.
Altogether the flow looks like this:

By leveraging this architecture, data contracts can be managed and enforced effectively, ensuring data consistency, compliance, and quality throughout the data lifecycle.
Glossary
Below you can find more information about the technologies and frameworks that our implementation relies on. Make sure you are familiar with them to have a deep understanding of the architecture of the system.
Data Contracts
Data contracts, in essence, are agreed-upon specifications or rules regarding data that is shared between systems or components. They define the shape, type, and other properties of the data being exchanged. A data contract assures data consumers about the quality and the form of data they receive from data producers. For more information, you can look at Andrew Jones informal introduction to data contracts or a more formal presentation of data contracts from Chad Sanderson. Also to know more about real-world data contracts systems you can find our previous iteration described here.
Data Producers & Data Consumers
Depending on the organization setup and tools Data Producers and Data Consumers may come in different flavors but the core of it stays the same: producers are the ones who make data available to consumers. Note that these are roles, not job titles. In larger organizations, you might find that one Data Consumer is a Data Producer for another team. For example, consider a manufacturing company using SAP and then dbt running on BigQuery. One team, called Alpha, handles SAP to BigQuery ingestion and they are the ultimate Data Producers for the company. The team of analytic engineers called Omicron takes this data and converts them into usable tables with orders, materials, and so on. After that another team, Omega takes this data and creates revenue datasets, while team Sigma creates tables for ML models predicting retail points sales. In this setup, Omicron is both the consumer (it needs data from Alpha) and the producer (serves the data for Omega and Sigma).
dbt (Data Build Tool)
dbt is an open-source, command-line tool that enables data analysts and engineers to transform data in their warehouses more effectively. It encourages adopting practices from software engineering, like version control, modularity, and testing, in a data analytics workflow. You can find more information about dbt on their product page or by following their free online courses, including dbt fundamentals.
Great Expectations
Great Expectations is a Python-based open-source library for validating, documenting, and profiling your data. It helps data teams eliminate pipeline debt, through data testing, documentation, and versioning. It supports different backends for running those checks, including in-memory Pandas, Apache Spark, and SQL alchemy, allowing you to plug it into any SQL database you want. On top of that, Great Expectations introduced GX Cloud, which enables your data teams with a web layer that helps track the execution of the validations. You can sign up for the Beta of GX Cloud here.
Data Mesh
A data mesh is an architectural paradigm that views data as a product. It emphasizes decentralizing data ownership and architecture, treating domains as sovereign with their data products. It contrasts with the traditional, centralized data lake or data warehouse approach. The best introduction to the concept still serves Zhamak’s (author of the concept) original article hosted by Martin Fowler on his blog.
Data Products
Data products are datasets that are designed, built, and managed to be ready for consumption and to provide meaningful insights. They adhere to the needs of the consumers and provide value, similar to any other product. The concept stems from Data Mesh and the idea to treat data as a product. Some compare Data Products to Microservices focusing on the similarities that can be found in the independent development, deployments, and maintenance of the two.
By understanding these concepts, we can better appreciate the design of our data contract system and how it leverages dbt, Google Cloud, and Great Expectations to ensure data integrity, reliability, and availability.
Conclusion
In the following parts of this series, we delve into more detail about how these elements interact within our data contract system. You can find Part 2 focusing on the implementation of the data contract management layer and Part 3 which covers the steps to build the data contract execution layer.
If you are looking for support on Data Stack or Google Cloud solutions, feel free to reach out to us at sales@astrafy.io.
Written by

Astrafy



