Blog
Exploring the power of dbt 1.9
Reading time.
2 min
Wrtitten by
Charles Verleyen
Analytics Engineering

Introduction
Every four months, dbt releases a new version of its dbt core and dbt adapters. In those first days of October, dbt 1.9.0 was released and came with a quite exciting feature. In this article, we will explore in depth the core feature of this release, which is “microbatch incremental” and also cover the other enhancements that came with this release.
Disclaimer: this release is still in beta and is expected to be GA by the first half of November 2024. Concepts and configurations described in this article are likely to to remain the same.
Microbatch incremental
dbt 1.9 introduces a new feature for incremental models: the microbatch strategy (full documentation here). Previously, incremental models could only process new data in batches based on a single column, often a timestamp. This could lead to performance bottlenecks when dealing with large volumes of data.
With microbatch, you can now define multiple batching columns, enabling dbt to process smaller, more manageable chunks of data. This translates to faster incremental model refreshes, reduced strain on your data warehouse, and, ultimately, more efficient data pipelines.
This approach offers several benefits:
Efficiency: By processing smaller chunks of data, you can optimize resource usage and reduce processing time.
Resiliency: If a batch fails, you can retry it without reprocessing other batches.
Concurrency: In future updates, batches can be processed concurrently, further speeding up data transformations.
Idempotency: Since each batch is independent, reprocessing a batch should yield the same result.
The biggest change with the previous incremental configuration is that you no longer need to specify an “is_incremental” clause in your model. When you run a microbatch model, dbt will evaluate which batches need to be loaded, break them up into a SQL query per batch, and load each one independently.
How does it work if you don’t have to specify incremental logic? Configurations for microbatch consist of four parameters, and the mechanic trick lies in the event_time parameter.
event_time: The column indicating “at what time did the row occur.” Required for your microbatch model and any direct parents that should be filtered. This last point is very important. The direct parent of your microbatch models also needs to have this parameter configured.
Begin: The “beginning of time” for the microbatch model. This parameter will be used in full-refresh builds to indicate the oldest history data we want to get.
Batch_size: The granularity of your batches. Supported values are hour, day, month, and year.
Lookback: Number batches before the latest bookmark to capture late-arriving records.
Let’s take a model “sessions.sql” with the following configuration and query:
This will translate into the following data processed based on the days the query runs:
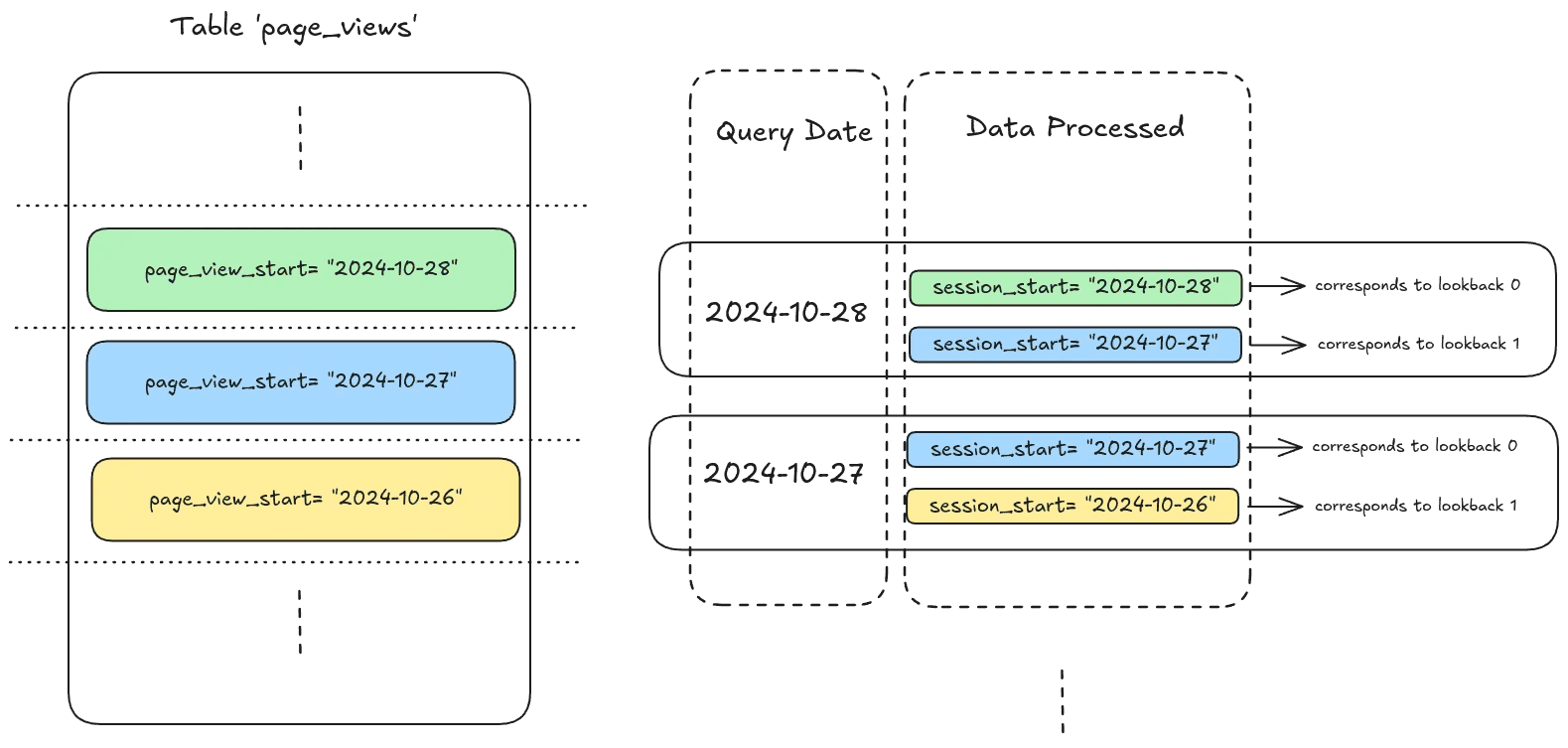
Each of the batches (in this case, each of the days processed) will launch separate independent queries in your query engines in a “divide and conquer” mode.
Those microbatches make it easier than ever to reprocess only specific batches of data from the past and, therefore, to reprocess historical data. Reprocessing data for the first five days of October is as simple as running the following dbt command:
Retrying failed batches is also made easier, and imagine you run a full refresh that goes two years back in time with a granularity of days. This will run more than 700 independent batches, and in case some batches fail, you can easily retry those by running the command “dbt retry”. The following illustration depicts a case with three batches having failed:

As with every new feature, it still has room for improvement, and I highly recommend reading Christophe Oudar’s article on this topic. His recommendations are quite valuable and should be taken into consideration by the dbt labs team for subsequent releases.
Snapshots Improvements
dbt 1.9 introduces some exciting updates to snapshots, making them more flexible and user-friendly. Here’s a breakdown of the key changes:
Snapshots in YAML
You can now define snapshots using YAML files instead of SQL. This brings consistency to defining sources in dbt and offers a cleaner approach.
YAML (snapshots/orders_snapshot.yml):
Need to apply transformations? No problem! Define an ephemeral model and reference it in your snapshot:
SQL (models/ephemeral_orders.sql):
YAML (snapshots/orders_snapshot.yml):
Optional target_schema
Previously, all snapshots were written to the same schema, regardless of the environment. Now, you have the flexibility to define different schemas for different environments (e.g., development, production) or use a single schema for all. This simplifies development workflows and gives you more control.
Customizable Meta Column Names
dbt automatically adds metadata columns to your snapshots (e.g., dbt_valid_from, dbt_valid_to). With dbt 1.9, you can customize these column names directly in your YAML configuration:
YAML (snapshots/orders_snapshot.yml):
These updates make dbt snapshots more powerful and easier to manage. For more details, check out the official dbt documentation: https://docs.getdbt.com/docs/build/snapshots
Conclusion
The article explored the two main features/improvements that make dbt 1.9 a worthwhile upgrade for any data professional. But this release comes as well with a bunch of noticeable enhancements:
Maintain data quality now that dbt returns an an error (versioned models) or warning (unversioned models) when someone removes a contracted model by deleting, renaming, or disabling it.
Document singular data tests.
Use ref and source in foreign key constraints.
Use dbt test with the — resource-type / — exclude-resource-type flag, making it possible to include or exclude data tests (test) or unit tests (unit_test).
As this version does not introduce any breaking changes, we highly recommend to upgrade your dbt projects to this version once the release is in GA. By keeping up with latest developments and leveraging latest features, you make it easy to maintain best practices, improve the efficiency and reliability of your data pipelines, and future-proof your dbt projects against potential compatibility issues.
Thank you
If you enjoyed reading this article, stay tuned as we regularly publish articles on dbt and analytics engineering in general. Follow Astrafy on LinkedIn, Medium, and Youtube to be notified of the next article.
If you are looking for support on Modern Data Stack or Google Cloud solutions, feel free to reach out to us at sales@astrafy.io.
Written by

Charles Verleyen
CEO & Lead Architect



