Blog
dbt 1.8 it is just wow
Reading time.
1 min
Wrtitten by
Charles Verleyen
Analytics Engineering

Introduction
Every four months, dbt releases a new version of its dbt core and dbt adapters. In those first days of May, dbt 1.8.0 was released and the latest features do not disappoint. In this article, we will deep dive into the core feature of this release which is “unit testing” and also cover other interesting features such as the “empty” flag. We will accompany those new features of code snippets with a public repository so you can try out those new features immediately on a sandbox project.
Disclaimer: This article is based on the official release documentation from dbt (link here). We are just extending it with a few more concepts and code snippets.
Installation
First things first; dbt has changed how you install it. And for the better you now have to do it in one command for dbt-core and for the adapter you use (i.e. the analytical database). For instance, if you are working with bigquery and want to install dbt, you have to run the following command
And you can always pin specific version as follows:
Core new features
1. Unit Testing
Testing has been a core aspect of dbt since its very beginning, ensuring the accuracy and integrity of your data. Until now, dbt had data integrity tests built-in and those tests' purpose is to check that the data itself meets some quality standards. For instance to check unique values in a column, make sure that the integers in a column are all positive, etc. Those tests are mainly to be set on the data you consume at the source to make sure you avoid the “Garbage in, garbage out” problem and that you only work with clean data from the beginning.
What dbt 1.8 brings to the table is “unit testing” and is similar to “unit testing” in software engineering. Here you want to ensure that the transformation you are writing in SQL leads to expected outputs given some raw inputs. Having unit tests in place is fundamental for complex SQL code for the following reasons:
Ensure transformation integrity
Ensure that other team members changing your SQL code later on will not alter the logic of your SQL
The illustration below depicts those two families of tests:
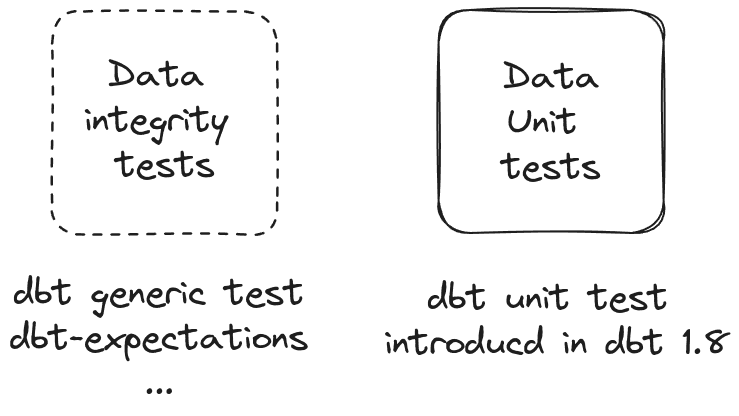
It is worth noting that some very decent dbt packages were already tackling this “unit testing” missing piece and at Astrafy we were using the package “dbt-unit-testing” from EqualExperts. This was doing the job quite well but having now those unit tests feature built-in within dbt is the approach to use.
When should you run your unit tests as compared to your data integrity tests?
Data integrity tests should run at every data pipeline run as those tests need to check every piece of new data to make sure it meets the quality checks in place. As per the flow hereafter depicting a typical data pipeline, data tests have to run at each pipeline run

Unit tests on the other hand should only run in CI pipeline when new code is pushed or merged. Indeed those unit tests run on mocked data and the purpose of those tests is to check the validity of your SQL transformations; those tests therefore only need to run when changes have been made to the code. The following CI workflow depicts where those units could run as dedicated stage:

Demo
Enough of the theory and concepts; let’s play with a concrete example. If you want to replicate the following example, we have got you covered with the repository accessible here.
Let’s consider a simple example where we want to validate the logic of an email validation function. We have a model named int_dim_customers and we want to check if our is_valid_email_address logic correctly identifies valid and invalid email addresses.
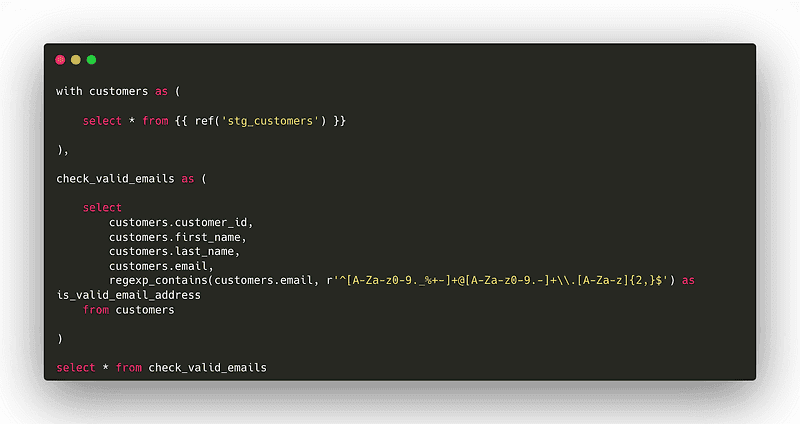
Unit tests should be defined in YAML files located within the /models directory. This ensures that the tests are closely associated with the models they are testing, making it easier to manage and maintain them.
A unit test block in dbt is designed to test specific logic within your models by mocking input data and specifying the expected output. Here is a breakdown of the key components of a unit test block:
name: The name of the unit test. This should be descriptive enough to understand what the test is checking.
description: A brief description of what the test is intended to verify.
model: The name of the model being tested. This is typically a reference to the model file or the model name within dbt.
given: This section specifies the input data to be used in the test.
input: A reference to the source table or staging table that serves as the input for the test.
expect: This section specifies the expected output data.
rows: A list of rows representing the mock input/output data. Each row is a dictionary where the keys are column names and the values are the data values.
Here is the configuration for our unit test:

This unit test checks that our is_valid_email_address function correctly identifies valid and invalid email addresses based on the given criteria. We specify the input data and the expected output for our test.
To run this unit test, we use the following command:

The output shows that our unit test failed because there was a difference between the actual and expected results. Specifically, the test expected cool@example.com to be valid, but the actual result marked it as invalid. This indicates that our email validation logic needs to be reviewed and corrected to handle this edge case properly.
Updating the regex logic and rerunning the unit test solves the problem:

By incorporating unit tests into your dbt workflow, you can catch and fix such issues early in the development process, ensuring higher data quality and reliability in your data transformations. For detailed documentation regarding those unit tests, you can refer to the official documentation here.
2. dbt dry run
In dbt 1.8.0, a valuable addition to the run command is the — empty flag. This flag enables the creation of schema-only dry runs, which can be particularly useful for validating model dependencies without incurring the cost of processing large datasets.
What Does the — empty flag Do?
When the — empty flag is used, dbt limits the rows returned by ref and source functions to zero. This means that while dbt will execute the model SQL against the target data warehouse, it will avoid expensive reads of input data. The primary benefits of this feature include:
Cost Efficiency: By preventing the reading of large datasets, the — empty flag generates no costs at all.
Dependency Validation: Even without reading data, dbt checks for model dependencies, ensuring that all references and sources are correctly set up.
Quick Schema Validation: This feature allows for quick validation that your models can build properly in terms of schema and dependencies, without the need to process and load large volumes of data.
For those of you using BigQuery, this is equivalent to a dry run and when using the — empty flag with the BigQuery adapter, dbt is calling this BigQuery dry run method.
Demo
Here’s what you might see when running a dbt command with the — empty flag:

In this output, the run was completed successfully without reading any data from the input tables (0.0 rows, 0 processed). This ensures that the schema and dependencies are validated without incurring the cost of large data reads.
This is a powerful tool for developers who need to validate their model schemas and dependencies without the overhead of processing large datasets. It enables cost-effective, quick checks to ensure that models will build properly, helping to streamline the development and testing process in dbt projects.
Other features/funcionnalities in dbt 1.8
To distinguish between data tests and unit tests, the “tests:” config has been renamed to “data_tests:” . Both are currently supported for backward compatibility.
Custom defaults of global config flags should be set in the flags dictionary in dbt_project.yml, instead of in profiles.yml.
New CLI flag — resource-type/ — exclude-resource-type for including/excluding resources from dbt build, run, and clone
Syntax for DBT_ENV_SECRET_ has changed to DBT_ENV_SECRET and no longer requires the closing underscore.
Conclusion
As a rule of thumb, you should always analyze in-depth the new features of a new major/minor version before upgrading. Upgrading just for the sake of being on the latest version is not a good idea, especially if the version you are on works well and does the job. This is different for patch updates (the latest x in semantic versioning x.x.x) where in that case you should always upgrade blindly as it mainly solves bugs and performance issues.
That being said, dbt 1.8 is one of those new versions that bring really lot of added value due to its unit testing. It has been a missing piece (and highly requested by the community) of dbt since the very beginning. Being able to test your SQL transformation with mocked data will increase significantly the quality of dbt projects by preventing erroneous transformations from being pushed/merged on specific branches.
As always, start small by implementing unit tests on your complex/sensitive transformations and then slowly adopt a test-driven development culture.
Thank you
If you enjoyed reading this article, stay tuned as we regularly publish technical articles on dbt and how to leverage it at best to transform your data efficiently. Follow Astrafy on LinkedIn, Medium, and YouTube to be notified of the next article.
If you are looking for support on Modern Data Stack or Google Cloud solutions, feel free to reach out to us at sales@astrafy.io.
Written by

Charles Verleyen
CEO & Lead Architect



