Blog
FinOps: Unveiling Clarity in Cloud Cost Management
Reading time.
1 min
Wrtitten by
Astrafy
Analytics Engineering

Introduction
Every Cloud practitioner has already been surprised by the unexpected cost of using Cloud technologies. Due to the “pay as you go” pricing model and ease of deploying resources, those unexpected surprises will continue to happen. But there are solutions to tackle those surge in cost issues. At Astrafy, we manage our clients’ billing data on Google Cloud and have set up various layers of defence against unexpected cost rises. One of those are budget alerts and expense reports sent through slack; those two solutions are described in detail in this article.
Another layer of defence described in this article is to have full visibility on your cloud costs (the inform phase of the FinOps framework). At Astrafy we have adopted a data mesh approach to our data and have different data products per data concepts. One of those data products is “FinOps’’ and contains all the data related to our Google Cloud costs. One data product translates into one dbt project with a specific data owner. This data product translates as well into one Airflow DAG (i.e. a data product DAG). This data product in the end provides curated datamart that can serve any kind of downstream applications. In our case it will be BI dashboards in Lightdash.
Astrafy’s spirit is to resolve data problems using Open Source software mostly. Utilising open-source technologies is fundamentally cost-efficient, freeing organisations from expensive licences and vendor restrictions, while allowing customization to meet unique needs. The ability to modify and tailor the software provides unmatched flexibility and freedom, enabling innovation and adaptability.
Data source
As stated in the introduction, we have exported cloud billing data from Google Cloud Platform of our clients to BigQuery. This is the source of all our dbt transformations.
This export permits us to retrieve all data about the billing activity of every customer (such as usage, cost estimates, and pricing data). It is fairly easy to understand the database produced. Each row in this billing export table in BigQuery corresponds to a spending on Google Cloud with maximum granularity.
dbt modelling / dbt transformations
Cloud billing raw data is streaming continuously into BigQuery and this table is our landing zone and source of truth for the transformation journey that will lead to curated datamarts. Those transformations are performed using dbt.
As always, we adhere to the industry’s best practices, which include:
Segmenting our dbt models into distinct data layers:
→ staging models,
→ data warehouse/intermediate models,
→ datamart models.
Setting ‘incremental’ for models that handle vast volumes of daily ingested data to avoid excessive data consumption.
Configuring clustering for often filtered fields, enhancing speed and cost-efficiency.
Maintaining separate production and development environments to prevent conflicts.
This approach ensures our work remains efficient and comprehensible for future reference. Initially, we utilised staging models primarily for basic 1-to-1 transformations from the sources, incorporating the “record_date” for incremental configuration. Following this, intermediate models house our data modelling logic, complete with full data historization. Lastly, datamart models, acting as final tables, are integrated into various downstream applications. During this phase, we pull information from either staging or intermediate models for further transformation.
For example, clients in the data sources are indirectly named, associated with a billing account id. In order to have a clear understanding of the client dealt with, the creation of a mapping table between the clients’ name and its billing account id was created. It is a CSV file that contains the relationship between the two elements. This csv is then translated into a materialized table using dbt seeds. It’s crucial to link the “billing_account_id” column with the “client_name” column from a corresponding database, enhancing clarity for future reference.
Additionally, our dbt project is structured such that local modifications are reflected in the BigQuery development environment, ensuring no impact on the unaffected production environment that operates exclusively through Airflow after updates via a GitLab CI. This structure guarantees the uninterrupted operation of existing systems.
All dbt models are scheduled for daily execution using Airflow, satisfying our need for daily data refreshes. However, this frequency is adjustable for more real-time monitoring requirements if needed.
The outlined architecture below illustrates the complete data flow, with data transitioning from left to right. The blue area denotes the diverse sources automatically populated by the log sink, while the green area represents the dbt transformation area, operated daily through Airflow, updating the datamarts in BigQuery.
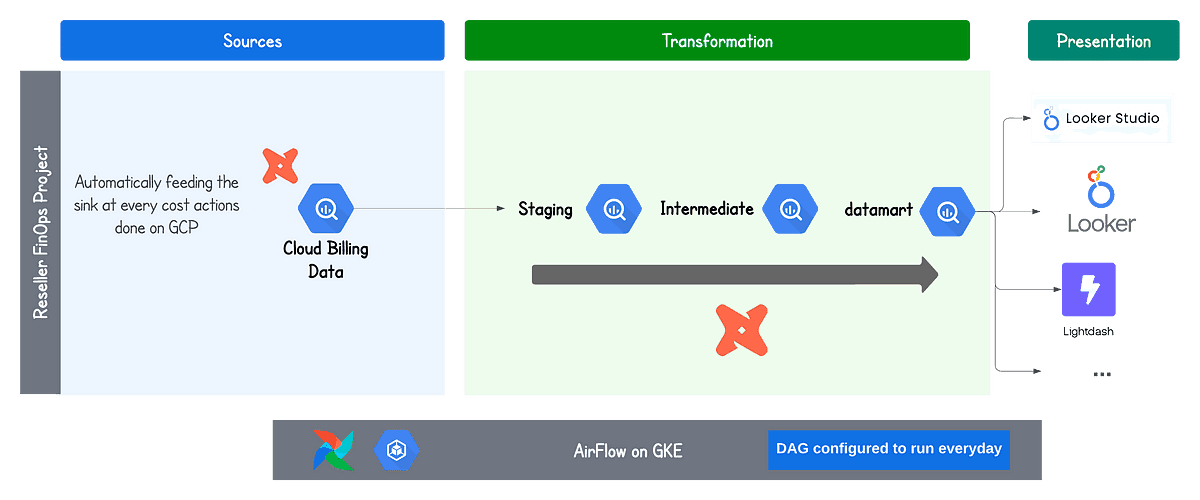
Data visualisation
Datamarts are primed for utilisation by Business Intelligence (BI) tools for dashboard creation. We employed two distinct tools for generating these visualisations. Initially, we utilised Looker, a tool from Google (leveraging our prior experience with this BI tool), making it an apt choice for our dashboard development. Conversely, we also used Lightdash, an open-source tool, to demonstrate our project’s compatibility and ease of use with various BI tools by recreating the same dashboards.
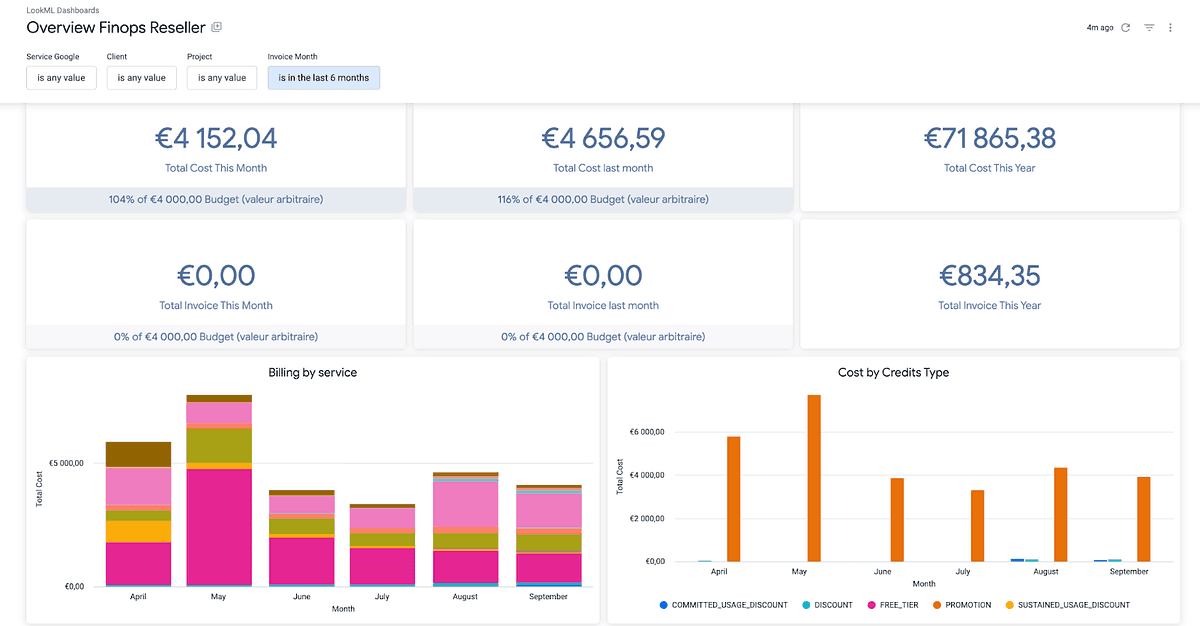

Our primary objective is to facilitate effortless access to client consumption information to promptly identify any irregular activities. Hence, we crafted a user-friendly dashboard that encapsulates crucial information including client billing costs, total invoices for the current and previous month, monthly credits offered by Google to clients, and the top 10 most costly Google services used.
For instance, an immediate alert would be dispatched to Slack or Email if a client’s monthly invoice cost overshoots a defined limit. This instant notification system ensures that we remain vigilant and can quickly respond to any anomalies, further solidifying our project’s reliability and our commitment to monitoring client activities effectively.
This approach underscores our commitment to ensuring extensive transformation before integrating the datamart with a data visualisation tool, enhancing the project’s compatibility with any BI tool such as Apache Superset, Looker, Lightdash, PowerBI, and others, making it accessible and convenient for all users.
Conclusion
In conclusion, at Astrafy, we take a proactive and efficient approach to monitor and manage unexpected cloud costs for our clients using the Google Cloud Platform. FinOps is a developing discipline and cultural practice in cloud financial management that helps organisations achieve maximum business value. It facilitates collaboration among engineering, finance, technology, and business teams, enabling them to make data-driven spending decisions.
This article delved further into the “Inform” phase, the foundational step of a FinOps project. Through the strategic exportation and transformation of cloud billing data to BigQuery, we ensure seamless, real-time insights into each customer’s billing activity. Our use of industry-standard BI tools like Looker and Lightdash for creating comprehensive dashboards underscores our commitment to providing easily accessible and understandable data for all our clients. By ensuring the integration and scheduling of dbt models and maintaining distinct data environments, we guarantee the uninterrupted and smooth operation of existing systems, thereby ensuring immediate alerts for any unusual activities in client billing.
Our methodical and strategic framework reinforces our determination to effectively oversee and handle cloud expenses, ensuring transparency, ease, and efficiency in cloud cost management for all clients. Following the Inform phase, the next step is Optimization. This step involves identifying and resolving cost anomalies, such as by refining queries in BigQuery to enhance their efficiency and using appropriate configurations like incremental adjustments, among others.

— — — — — — — — — — — — — — — — — — — — — — — -
If you enjoyed reading this article, stay tuned as more articles will come in the coming weeks on exciting data solutions we build on top of generic Google Cloud data. Follow Astrafy on LinkedIn to be notified for the next article ;).
If you are looking for support on Data Stack or Google Cloud solutions, feel free to reach out to us at sales@astrafy.io.
Written by

Astrafy



