Understand the implications of running dbt in different environments focusing on Google Cloud
Running dbt in production has become one of the commonly asked questions among dbt practitioners. There is already a lot of information on how to do this correctly. However, information from different sources is usually contradictory, which makes it difficult to select a strategy due to the lack of consensus.
dbt itself does not provide guidelines on this topic. Understandably, taking into account they want to promote their cloud model, instead of helping people deploy their own infrastructure to use dbt.
You may wonder if I am going to do exactly the same and explain the methodology I follow to deploy dbt in production. The answer is yes. However, first I will go through the different strategies to deploy dbt in production so you have a clear picture of the distinct ways you can use dbt.
Strategies to deploy dbt in production
First of all, it is important to identify the requirements of the infrastructure to evaluate the different options concerning these characteristics. Here is a list of what a typical dbt environment should aim to achieve:
Scheduling: The environment should support the automated execution of jobs at predefined times or intervals. This ensures that data transformation tasks are performed regularly without manual intervention, keeping the data up-to-date.
Scalability: The environment should be able to scale to handle growing data volumes and the complexity of transformations without significant degradation in performance.
Reliability: Ensuring the reliability of the infrastructure surrounding dbt involves implementing robust measures to maintain a low error rate throughout data transformation processes.
Version Control: Effective version control mechanisms are essential for managing dbt packages and their dependencies. This ensures that all environments (development, testing, production) use compatible versions, reducing conflicts and the ability to roll back to previous versions.
Monitoring and Logging: Comprehensive monitoring and logging capabilities to track the execution of dbt jobs, performance metrics, and any issues that arise during data transformation processes.
Several more characteristics, such as security, are also important. However, let’s assume those are covered since all infrastructure designs already assume security or they are not even considered (such as running it locally).
Now, let’s look at the three main strategies we can follow given these requirements. These are CI/CD pipelines, Cloud Run, and orchestrators.
1. CI/CD pipelines
Several services exist such as GitHub Actions or Gitlab CI/CD pipelines. They are pretty easy to use and have direct access to your dbt code, which is a great advantage for simplicity. The feature of running jobs in a schedule also simplifies orchestration and automation. The workflow will be the following:
Checkout the repository to have access to your dbt models
Download the dependencies
Perform the dbt operations (seed, run, build, test…)
As simple as that. This is the first approach of running dbt in production. Of course, the simplicity comes at a cost. However, we can say that this is the “minimal” needed to have a production environment that fulfills our requirements mentioned above.
A GitHub action to represent this process will look like the following.
name: Run dbt
<p>on:<br>push:<br>branches:<br>- main<br>schedule:<br># Scheduled at 05:00 every day<br>- cron: '0 5 * * *'</p>
<p>jobs:<br>run-dbt:<br>runs-on: ubuntu-latest<br>steps:<br>- uses: actions/checkout@v2</p>
<pre><code>- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.8'
- name: Install dbt
run: pip install dbt-core dbt-postgres
- name: Run dbt commands
run: |
dbt deps
dbt run
dbt test</code></pre><p>A good improvement of this strategy would be running different models on different stages. This allows easier debugging and re-executing in case of errors.</p><p>The simplicity and setup easiness are clear, but it comes with drawbacks.</p><ul><li data-preset-tag="p"><p><strong>Lack of Advanced Monitoring and Alerts</strong>: While these solutions often provide some monitoring capabilities, they might not offer the advanced monitoring, logging, and alerting features that are needed for a production environment. This can make it challenging to diagnose and respond to issues in real-time.</p></li><li data-preset-tag="p"><p><strong>Workflow complexity</strong>: As your data operations grow in complexity, the workflows required to manage them might become too cumbersome for a CI/CD pipeline, which is not primarily designed for data pipeline orchestration.</p></li><li data-preset-tag="p"><p><strong>Lack of versioning: </strong>Even if some basic versioning exists with commits, it will be hard to debug which version is running at any point, roll back in case of problems with the latest version, and have difficulty keeping control of what version is currently being run.</p></li><li data-preset-tag="p"><p><strong>Environment Isolation</strong>: Running production jobs in CI/CD pipelines might not provide the same level of environment isolation as more dedicated solutions, potentially leading to issues with reproducibility and consistency.</p></li></ul><p>The last point can be solved by building a custom image that is used specifically for the CI/CD pipeline. That increases the complexity and I would argue that if you plan to increase complexity, it would be better to move to a different solution directly. Do not waste time improving on this solution because unless your data pipelines are really simple and not expected to grow, you will eventually move out of it.</p><h3>2. Cloud Run</h3><p>Cloud Run is a service included in Google Cloud that allows running container images as a one-off. Similar products are available in AWS and Azure, which the comparison also applies to.</p><p>The workflow to run dbt using this solution will be similar to the following.</p><img alt=" The image is a simplified diagram of a CI/CD pipeline using cloud services. It shows a sequence from Git repository to Cloud Build, Artifact Registry, Cloud Run, and BigQuery, with Cloud Scheduler as an additional trigger for Cloud Run. The diagram illustrates code integration, building, artifact storage, deployment, data handling, and scheduled task automation." src="https://framerusercontent.com/images/QAQW0YRQgTcii4gm7pXri8uOEVI.png"><ul><li data-preset-tag="p"><p>Having the dbt code in the git repository of your choice, by tagging the repository will trigger a CI/CD pipeline. It could be GitHub actions, GitLab CI/CD, Cloud Build, Jenkins, or similar.</p></li><li data-preset-tag="p"><p>This pipeline will perform several tasks such as quality checks, dbt compilation, and SQL formatting. The key step for our workflow is building the image containing the dbt code. It can be as simple as the following.<br><br></p></li></ul><pre data-language="YAML"><code># Use the official Python image. python:3.9.18-alpine3.18
name: Run dbt
<p>on:<br>push:<br>branches:<br>- main<br>schedule:<br># Scheduled at 05:00 every day<br>- cron: '0 5 * * *'</p>
<p>jobs:<br>run-dbt:<br>runs-on: ubuntu-latest<br>steps:<br>- uses: actions/checkout@v2</p>
<pre><code>- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.8'
- name: Install dbt
run: pip install dbt-core dbt-postgres
- name: Run dbt commands
run: |
dbt deps
dbt run
dbt test</code></pre><p>A good improvement of this strategy would be running different models on different stages. This allows easier debugging and re-executing in case of errors.</p><p>The simplicity and setup easiness are clear, but it comes with drawbacks.</p><ul><li data-preset-tag="p"><p><strong>Lack of Advanced Monitoring and Alerts</strong>: While these solutions often provide some monitoring capabilities, they might not offer the advanced monitoring, logging, and alerting features that are needed for a production environment. This can make it challenging to diagnose and respond to issues in real-time.</p></li><li data-preset-tag="p"><p><strong>Workflow complexity</strong>: As your data operations grow in complexity, the workflows required to manage them might become too cumbersome for a CI/CD pipeline, which is not primarily designed for data pipeline orchestration.</p></li><li data-preset-tag="p"><p><strong>Lack of versioning: </strong>Even if some basic versioning exists with commits, it will be hard to debug which version is running at any point, roll back in case of problems with the latest version, and have difficulty keeping control of what version is currently being run.</p></li><li data-preset-tag="p"><p><strong>Environment Isolation</strong>: Running production jobs in CI/CD pipelines might not provide the same level of environment isolation as more dedicated solutions, potentially leading to issues with reproducibility and consistency.</p></li></ul><p>The last point can be solved by building a custom image that is used specifically for the CI/CD pipeline. That increases the complexity and I would argue that if you plan to increase complexity, it would be better to move to a different solution directly. Do not waste time improving on this solution because unless your data pipelines are really simple and not expected to grow, you will eventually move out of it.</p><h3>2. Cloud Run</h3><p>Cloud Run is a service included in Google Cloud that allows running container images as a one-off. Similar products are available in AWS and Azure, which the comparison also applies to.</p><p>The workflow to run dbt using this solution will be similar to the following.</p><img alt=" The image is a simplified diagram of a CI/CD pipeline using cloud services. It shows a sequence from Git repository to Cloud Build, Artifact Registry, Cloud Run, and BigQuery, with Cloud Scheduler as an additional trigger for Cloud Run. The diagram illustrates code integration, building, artifact storage, deployment, data handling, and scheduled task automation." src="https://framerusercontent.com/images/QAQW0YRQgTcii4gm7pXri8uOEVI.png"><ul><li data-preset-tag="p"><p>Having the dbt code in the git repository of your choice, by tagging the repository will trigger a CI/CD pipeline. It could be GitHub actions, GitLab CI/CD, Cloud Build, Jenkins, or similar.</p></li><li data-preset-tag="p"><p>This pipeline will perform several tasks such as quality checks, dbt compilation, and SQL formatting. The key step for our workflow is building the image containing the dbt code. It can be as simple as the following.<br><br></p></li></ul><pre data-language="YAML"><code># Use the official Python image. python:3.9.18-alpine3.18
name: Run dbt
<p>on:<br>push:<br>branches:<br>- main<br>schedule:<br># Scheduled at 05:00 every day<br>- cron: '0 5 * * *'</p>
<p>jobs:<br>run-dbt:<br>runs-on: ubuntu-latest<br>steps:<br>- uses: actions/checkout@v2</p>
<pre><code>- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.8'
- name: Install dbt
run: pip install dbt-core dbt-postgres
- name: Run dbt commands
run: |
dbt deps
dbt run
dbt test</code></pre><p>A good improvement of this strategy would be running different models on different stages. This allows easier debugging and re-executing in case of errors.</p><p>The simplicity and setup easiness are clear, but it comes with drawbacks.</p><ul><li data-preset-tag="p"><p><strong>Lack of Advanced Monitoring and Alerts</strong>: While these solutions often provide some monitoring capabilities, they might not offer the advanced monitoring, logging, and alerting features that are needed for a production environment. This can make it challenging to diagnose and respond to issues in real-time.</p></li><li data-preset-tag="p"><p><strong>Workflow complexity</strong>: As your data operations grow in complexity, the workflows required to manage them might become too cumbersome for a CI/CD pipeline, which is not primarily designed for data pipeline orchestration.</p></li><li data-preset-tag="p"><p><strong>Lack of versioning: </strong>Even if some basic versioning exists with commits, it will be hard to debug which version is running at any point, roll back in case of problems with the latest version, and have difficulty keeping control of what version is currently being run.</p></li><li data-preset-tag="p"><p><strong>Environment Isolation</strong>: Running production jobs in CI/CD pipelines might not provide the same level of environment isolation as more dedicated solutions, potentially leading to issues with reproducibility and consistency.</p></li></ul><p>The last point can be solved by building a custom image that is used specifically for the CI/CD pipeline. That increases the complexity and I would argue that if you plan to increase complexity, it would be better to move to a different solution directly. Do not waste time improving on this solution because unless your data pipelines are really simple and not expected to grow, you will eventually move out of it.</p><h3>2. Cloud Run</h3><p>Cloud Run is a service included in Google Cloud that allows running container images as a one-off. Similar products are available in AWS and Azure, which the comparison also applies to.</p><p>The workflow to run dbt using this solution will be similar to the following.</p><img alt=" The image is a simplified diagram of a CI/CD pipeline using cloud services. It shows a sequence from Git repository to Cloud Build, Artifact Registry, Cloud Run, and BigQuery, with Cloud Scheduler as an additional trigger for Cloud Run. The diagram illustrates code integration, building, artifact storage, deployment, data handling, and scheduled task automation." src="https://framerusercontent.com/images/QAQW0YRQgTcii4gm7pXri8uOEVI.png"><ul><li data-preset-tag="p"><p>Having the dbt code in the git repository of your choice, by tagging the repository will trigger a CI/CD pipeline. It could be GitHub actions, GitLab CI/CD, Cloud Build, Jenkins, or similar.</p></li><li data-preset-tag="p"><p>This pipeline will perform several tasks such as quality checks, dbt compilation, and SQL formatting. The key step for our workflow is building the image containing the dbt code. It can be as simple as the following.<br><br></p></li></ul><pre data-language="YAML"><code># Use the official Python image. python:3.9.18-alpine3.18
The pipeline uploads the dockerize image to Google’s artifact registry (or any other registry of your choice).
A Cron scheduler such as Cloud Scheduler will trigger Cloud Run with the corresponding image in scheduled intervals.
The dbt pipeline will be executed and transform the corresponding data in BigQuery (or similar).
This workflow is very simple and effective for small pipelines. Its best advantage is the simplicity. This procedure can be set up in a couple of hours and you have your production pipeline already running.
It includes the usage of images rather than raw code, which is very useful to avoid the common “it works on my PC” situations. In general, it is best to avoid any solution that doesn’t imply using docker images.
However, the simplicity comes at a cost. When dbt models start growing in number and complexity, it will be very difficult to manage the executions. In this strategy, there is a lack of traceability (which of these runs correspond to this specific dbt project?). There is the UI available to check the executions, but the lineage is difficult to achieve.
Furthermore, executing the dbt models entirely on one run is not a best practice. Ideally, it is best to diversify the models in stages. You can run first your raw models, then your staging models to finally run the datamart models.
Besides, there is a lack of advanced orchestration features. As the data pipeline grows, the need for advanced orchestration features such as dynamic dependency resolution, conditional execution, and complex workflow management becomes mandatory.
Finally, the last point to mention is the inability to add dependencies between different data pipelines. You may have pipelines that depend on each other. In this case, advanced orchestration features are needed, which will become hard to develop and maintain using this strategy.
3. Orchestrator
Using an orchestrator is a choice that makes the overall architecture more complex. It needs to be set up, configured, and connected with dbt and the underlying data warehouse. As Airflow is the most commonly used orchestrator, we include it in the diagram of the architecture.
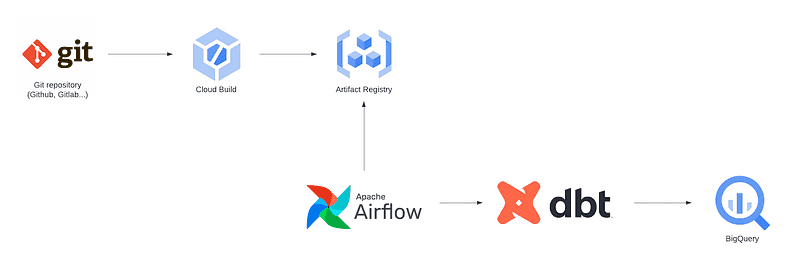
The first three steps of the strategy are exactly the same as those from the Cloud Run strategy, which makes migrations easier if you want to move from one to another. This is thanks to using containers, which are portable and very handy to use.
The main difference is that any orchestrator offers a much more advanced monitoring and logging interface, meaning better traceability which eases debugging and error resolution. They also have a built-in scheduler so we don’t have to depend on a different solution.
Another key point is being able to execute dbt commands in isolated containers independent from each other. Running the different stages of models (such as raw, staging, and datamart) independently allows us to retry only a portion of models rather than all of them when a failure occurs. Granularity is convenient to convert into little pieces a dbt project that could have several dozens of models.
Furthermore, the ability to execute different tasks unrelated to dbt is very handy. You can save elementary reports (a document-focused dbt package), trigger different pipelines when dbt has succeded, etc. This advances orchestration tools that are harder to integrate and difficult to maintain.
Conclusions
Unless your dbt project is really small and it is not likely to fail, the best option is to use an orchestrator. As we’ve seen, orchestrators such as Airflow provide advanced monitoring, logging, and the ability to execute dbt commands in isolated containers.
This level of granularity and flexibility is essential for managing complex data pipelines effectively. The comparison between CI/CD pipelines, Cloud Run, and orchestrators highlights that while simpler methods might work for small-scale projects, they lack the advanced features needed for robust, scalable, and reliable data transformation in production environments.
In conclusion, choosing the right strategy for running dbt in production depends on the specific requirements of your project. For smaller projects with less complexity, CI/CD pipelines or Cloud Run could provide a quick and simple solution.
However, for larger, more complex projects where reliability, scalability, and detailed monitoring are crucial, orchestrators like Airflow prove to be the superior choice. They offer the advanced features needed to manage intricate data workflows, ensuring your data transformation processes are efficient, reliable, and maintainable. As the complexity of your dbt project grows, transitioning to an orchestrator will likely become an inevitable step to ensure the continued success of your data operations.
Thank you
If you enjoyed reading this article, stay tuned as we regularly publish technical articles on dbt, Google Cloud and how to secure those tools at best. Follow Astrafy on LinkedIn to be notified for the next article ;).
If you are looking for support on Data Stack or Google Cloud solutions, feel free to reach out to us at sales@astrafy.io.





