Blog
Dynamic Data Pipelines with Airflow Datasets and Pub/Sub
Reading time.
1 min
Wrtitten by
Nawfel Bacha
Data Engineering

Introduction
In this article, we will discuss how Airflow Datasets are a game changer in Airflow as they add a new triggering functionality on top of manual triggering and scheduling. As your data pipelines get more complex and require to get triggered when a different set of actions are met, then Airflow Datasets come in very handy.
This article aims to provide a clear and comprehensive understanding of Airflow Datasets concepts, equipping you with the knowledge to apply them effectively in your projects.
This article will provide a concrete example using Google Cloud Pub/Sub as one of the upstream providers for the dataset.
Understanding Airflow Datasets
What Are Airflow Datasets?
Airflow Datasets are a powerful feature that enables you to manage dependencies between tasks in your workflows more effectively. It is a logical grouping of data where upstream producer tasks can update datasets, and dataset updates contribute to scheduling downstream consumer DAGs.

Traditionally, task dependencies in Airflow are hardcoded, making workflows rigid and challenging to maintain. Airflow Datasets offer a more dynamic approach, allowing tasks to be triggered based on the availability of required data rather than predefined schedules.
Benefits of Using Datasets
The primary advantage of using Airflow Datasets lies in simplifying dependency management. By triggering tasks dynamically as data becomes available, you reduce the complexity of your Directed Acyclic Graphs (DAGs), enhancing their maintainability and readability. This flexibility is especially beneficial in complex workflows, allowing for more adaptive and efficient data processing.
Consider a scenario where multiple data sources feed into a single processing pipeline. Without Airflow Datasets, you’d need to set rigid schedules or constantly poll for data readiness, both of which can lead to inefficiencies. With datasets, each processing task is triggered precisely when the necessary data is available, optimizing the workflow’s execution and reducing unnecessary overhead.

Dynamic Workflow Orchestration
Dynamic workflow orchestration refers to the ability to adjust and control workflows in real time based on changing conditions, such as data availability. Unlike static workflows that adhere to a fixed schedule, dynamic workflows react to real-time events, ensuring tasks are executed at the most appropriate time. The benefits are:
Flexibility: Dynamic workflows can adapt to real-time data events, ensuring tasks are executed when the data is ready.
Scalability: As data volumes grow, dynamic workflows can scale seamlessly, handling increased loads without manual intervention.
Real-Time Responsiveness: By reacting to data events as they occur, dynamic workflows reduce latency and improve overall pipeline efficiency.
Implementing dynamic workflows requires a robust system capable of monitoring data events and triggering tasks in response. This is where Airflow Datasets and Pub/Sub messaging come into play, providing the necessary tools to build these responsive workflows.
Managing Multi-DAG Dependencies with Multi-Dataset Listening
Complex Data Pipelines
In large-scale data processing environments, it’s common to have multiple DAGs that depend on each other. As the number of DAGs grows, managing these interdependencies becomes increasingly complex. The illustration below depicts how DAGs dependency can become complex over time.
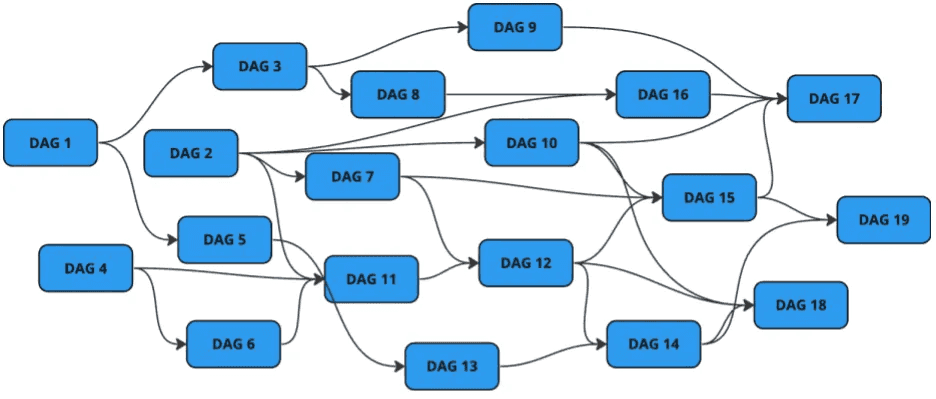
Before diving into Airflow Datasets, let’s briefly summarize the other methods for managing cross-DAG dependencies in Airflow:
TriggerDagRunOperator allows downstream DAGs to start as soon as tasks in an upstream DAG are complete, offering a straightforward push-based solution.
Sensors provide a pull-based approach, where tasks in a downstream DAG wait for specific events in upstream DAGs before executing.
Airflow API enables cross-environment DAG triggering via HTTP requests, ideal for workflows spread across different Airflow instances.
If you want to know more about those methods, this Medium article from Frederic Vanderveken is an excellent read. Below is a comparison table taken from this article:

Each method offers a unique way to manage dependencies effectively, ensuring your workflows remain synchronized and efficient. The Dataset method stands out as the most convenient and powerful approach for managing cross-DAG dependencies in Airflow. Its event-driven nature eliminates the need for additional operators, simplifying implementation and reducing maintenance overhead. Moreover, the Dataset method’s ability to handle complex “many-to-many” configurations allows for sophisticated workflows that are difficult, if not impossible, to achieve with other methods. This flexibility makes it the clear choice for building dynamic, scalable, and maintainable data pipelines.
Airflow Multi-Dataset
Airflow introduces the concept of multi-dataset listening to address the complexity of managing dependencies across multiple DAGs. This feature allows tasks within a DAG to be triggered by the availability of multiple datasets, rather than relying solely on time-based scheduling or single-task dependencies.
With this capability, a DAG can listen to and respond to updates from multiple datasets, enabling “many-to-many” configurations. This approach makes your workflows significantly more dynamic and responsive, ensuring that all necessary conditions are met before execution proceeds. By leveraging multi-dataset listening, you can simplify dependency management, enhance workflow reliability, and increase the overall efficiency of your data pipelines.
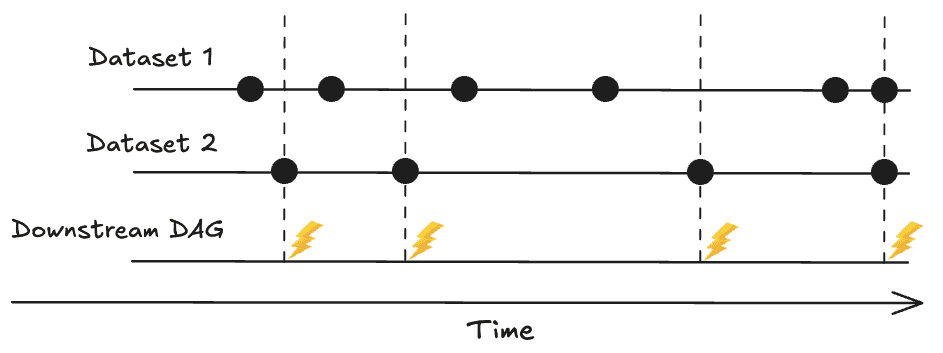
Example Scenario
Let’s consider a few practical scenarios where multi-dataset listening can be particularly beneficial:
Global Data Consolidation: Imagine a scenario where your organization has separate DAGs for processing sales data from different geographical regions, such as North America, Europe, and Asia. Each region processes its data independently, but at the end of the day, you need to consolidate all this data to generate a global sales report. With multi-dataset listening, you can set up a DAG that triggers only when datasets from all regions are updated. This ensures that the global report is generated only when the data from all regions is available and up-to-date.
Cross-Departmental Data Processing: In a large enterprise, different departments may have their own data processing workflows. For example, the finance department might run a DAG to close the books at the end of the month while the HR department processes payroll data in a separate DAG. However, the payroll data needs to include finalized financial data. By using multi-dataset listening, the payroll processing DAG can be set to trigger only when the finance department has completed its workflow, ensuring that payroll calculations are accurate and based on the latest financial data.
Real-Time Data Synchronization: For real-time analytics, it’s crucial that data streams from different sources are synchronized. Suppose you are running a streaming data pipeline where logs are ingested from various microservices into separate DAGs. Before running analytics tasks that correlate these logs, you need to ensure that logs from all relevant services have been ingested and processed. Multi-dataset listening allows you to coordinate these tasks effectively, ensuring that your analytics only run when all the necessary log data is available.
Implementation
Implementing multi-dataset listening in Airflow involves a few key steps:
You need to define the datasets that your DAGs will listen to. A dataset in Airflow can be thought of as a logical representation of a data source or output. You can define these datasets within your DAGs using the Dataset class:

Once your datasets are defined, you can configure tasks within your DAGs to listen for updates on these datasets. This is done by setting the outlets and inlets parameters within your tasks.
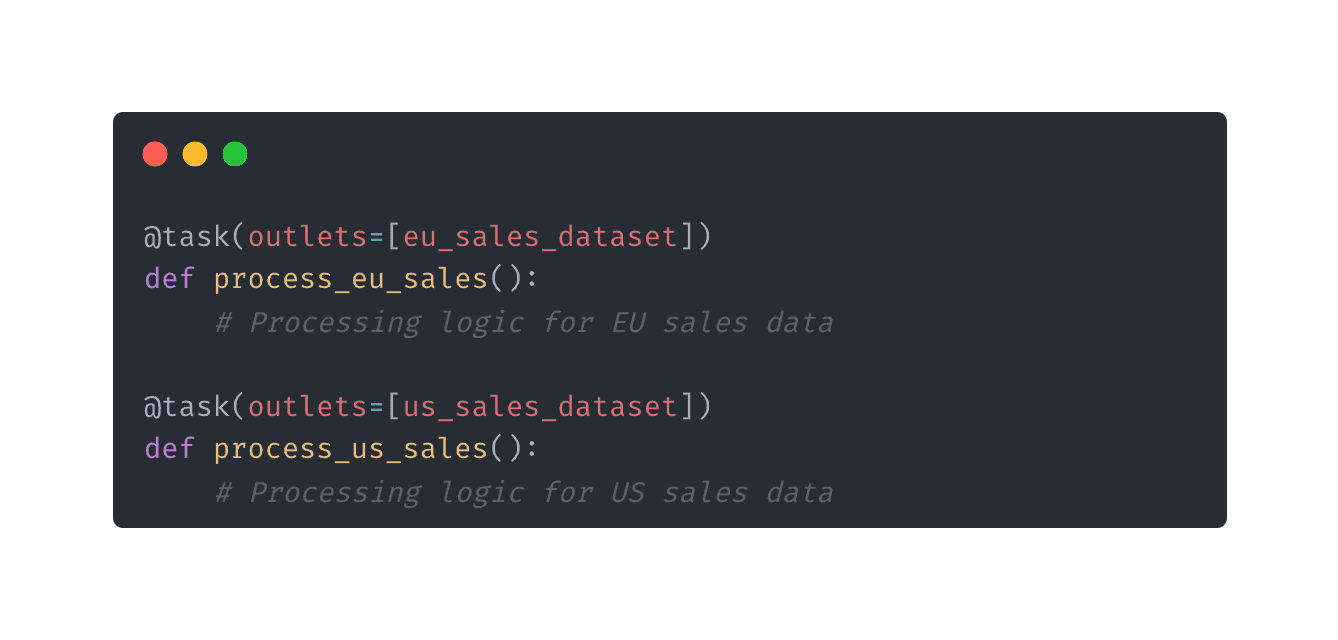
To implement multi-dataset listening, you’ll configure dags to trigger based on the availability of multiple datasets. This can be done by using the schedule parameter in your dag definition, specifying that the dag should only execute when all specified datasets are updated.

Dynamic Data Pipelines with Pub/Sub
In this section, we will dive into a concrete example leveraging Airflow Datasets and using Pub/Sub as one of the upstream producers for the Datasets.

Google Cloud Pub/Sub is a messaging service that facilitates the construction of dynamic data pipelines. It enables asynchronous communication between different system components, allowing you to easily publish and subscribe to messages.
You can create event-driven workflows by integrating Pub/Sub with Airflow Dataset. Instead of relying on fixed schedules, you can trigger tasks in response to real-time data events, making your data pipelines more efficient and responsive.
Let’s explore a concrete example of how a global e-commerce company can use Airflow Datasets and Pub/Sub to build a dynamic data workflow.
Scenario:
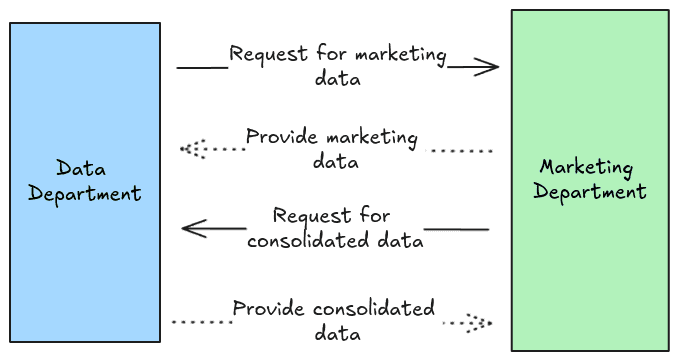
A global e-commerce company processes payment transactions from customers in Europe (EU) and the United States (US). The company’s central data team, responsible for consolidating data from various sources, needs to provide the marketing team with consolidated global sales data to analyze trends, customer behavior, and campaign effectiveness.
DAG A: Data Ingestion and Transformation
EU Payment Data Ingestion Task: Ingests payment transaction data from the EU, ensuring GDPR compliance, and loads the data into BigQuery.
US Payment Data Ingestion Task: Ingests payment transaction data from the US, validating the data for CCPA compliance.
Data Processing:
EU: Calculates and appends VAT information to each transaction.
US: Converts all transaction amounts to EUR based on the current exchange rate.
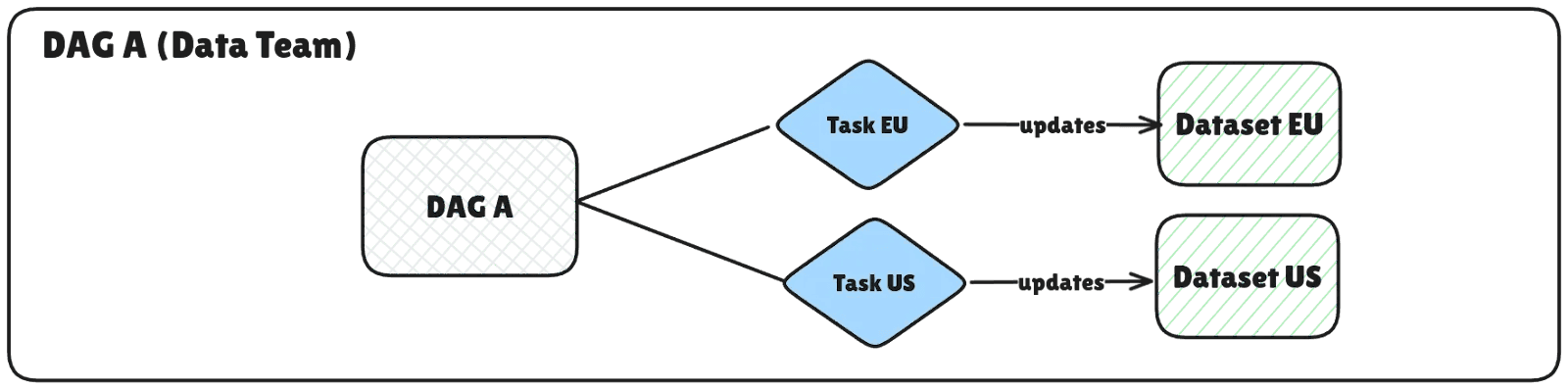
DAG B: Data Consolidation
Multi-Dataset Listening: A dataset is created for each region. When the ingestion and processing of EU and US data are completed, DAG B is triggered by the dataset updates.
Data Consolidation: DAG B consolidates the data from both regions, ensuring a unified dataset.
Notification: Once the consolidation is complete, a Pub/Sub message is sent to notify the marketing team that the data is ready for analysis.

DAG C: Marketing Analysis
Real-Time Trigger: The marketing team has a DAG that listens for the Pub/Sub message from the central data team. When the message is received, the DAG triggers the marketing team’s data processing tasks, allowing them to analyze the new, consolidated data immediately.

Conclusion
In this article, we’ve explored the concepts of Airflow Datasets, and this feature can be used with Pub/Sub to build dynamic, responsive data pipelines. By leveraging these technologies, you can simplify dependency management and enhance workflow flexibility. Whether you’re managing a single DAG or a complex network of workflows, these tools can help you create more efficient, scalable, and maintainable data pipelines.
P.S: If you want to dive deeper into how those concepts can be practically implemented, join us at the Airflow Summit 2024 in San Francisco. We will be presenting “Airflow Datasets and Pub/Sub for Dynamic DAG Triggering” on September 10th from 15:10–15:35 (San Francisco time). The recording will be available a few days later on YouTube.
Thank you
If you enjoyed reading this article, stay tuned as we regularly publish data engineering articles on Airflow and other mainstream technologies. Follow Astrafy on LinkedIn, Medium, and Youtube to be notified of the next article.
If you are looking for support on Modern Data Stack or Google Cloud solutions, feel free to reach out to us at sales@astrafy.io.
Written by

Nawfel Bacha
Data Engineer



