Blog
Google Cloud Expenses Summary Report
Reading time.
2 min
Wrtitten by
Charles Verleyen
Google Cloud
FinOps

You can’t control what you can’t measure
Introduction
Everyone using the cloud has already experienced some unexpected cost bursts. Due to the “pay as you go” pricing model and ease of deploying resources, those unexpected surprises will continue to happen. But you don’t have to discover those unexpected costs when receiving your monthly invoice; you need to get in control of all your spending in a dynamic way. FinOps starts with measuring and displaying your costs via convenient channels.
This article will go over a mechanism that dispatches every morning a detailed cloud expenses report (screenshot below). This report accomplishes various objectives:
Inform stakeholders about yesterday expenses
Accessible to everyone and fully automated
Act on unexpected costs and avoid bad surprises with your cloud invoice at end of the month
Recommended architecture
Leveraging best-in-class open-source tools with scalable Google Cloud products, we have come up with the following architecture:
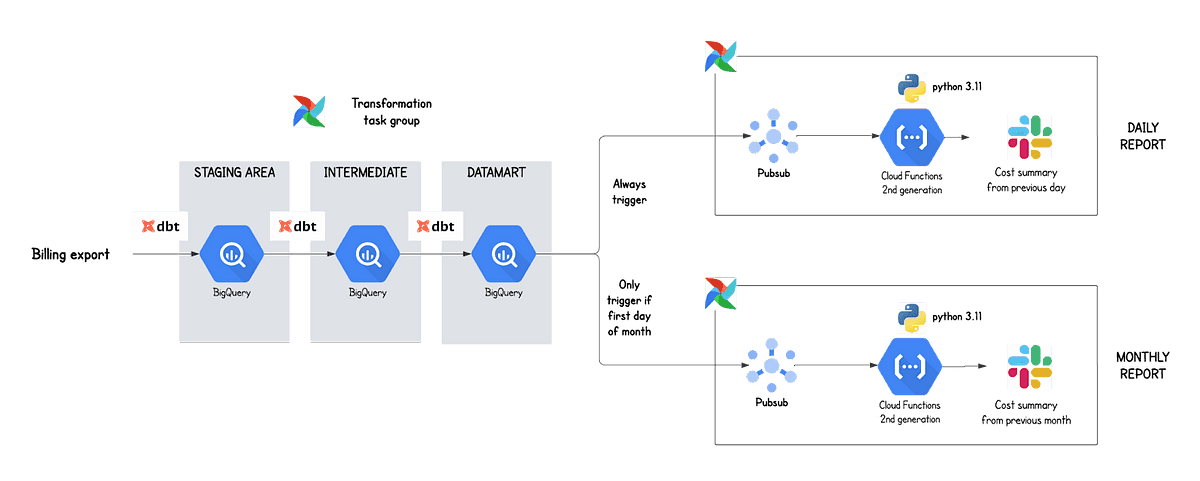
It all starts with the Google Cloud billing data export that contains granular data about all your organization costs. This data is then transformed with dbt through various data layers. Once the datamart tables are materialized (last data layer), a message is sent to a Pub/Sub topic that will trigger a Cloud Function that will dispatch the expense summary report. On the first of each month, a message is also sent to a separate Pub/Sub topic that will lead to the generation of a monthly expense report. Logic can easily be extended to other report frequencies (quarterly, yearly, etc.) by adding new aggregated report tables.
We are using Airflow as an orchestrator to orchestrate all the previous operations. This DAG is scheduled to run every day in the afternoon because we noticed that around 20% of the data from the previous day was not yet present in the morning. We prefer to wait a bit more and have a more accurate report than having the report early but with significant discrepancy with reality.
All our code is modularized into separate git repositories — this has the advantage of making it easy to change the logic of one component without affecting other components.
In terms of environment, we have one DEV and one PRD environment that are totally isolated from each other.
This simple yet very efficient architecture will be explained in detail in the following section.
Implementation
dbt
At Astrafy we have adopted a data mesh approach to our data and have different data products per data concepts. One of those data products is “FinOps” and contains all the data related to our Google Cloud costs. One data product translates into one dbt project with a specific data owner. This data product translates as well into one Airflow DAG (i.e. a data product DAG).
The dbt project takes a source the Google Cloud billing export data and then transforms this data into staging, intermediate and datamart views/tables. The datamart tables are then used by downstream applications to serve different use cases; this expense summary report being one of those.
dbt contains all the transformations and semantic layers so that the downstream applications do not have to carry out any kind of transformations. This makes it easier to maintain and avoid ending up with every downstream application reinventing the wheel.
dbt runs via a Kubernetes Pod Operator in Airflow and it runs as three different tasks:
One task for the staging transformation
One task for the intermediate transformation
One task for the datamart transformation
Those three tasks are then grouped into one Airflow task group.
Pub/Sub
GCP Pub/Sub is a messaging service that provides reliable, real-time messaging. In the context of this expense report, Pub/Sub messages are sent to trigger Cloud Functions which execute the dispatch to slack of the expense report. The message is fired to the Pub/Sub topic from an operator in Airflow.
The use of Pub/Sub to trigger at Astrafy provides several benefits, including fast, reliability and scalability. Moreover, Pub/Sub and Cloud Functions can be used to build event-driven architecture that respond to real-time data changes (We will have an article about this topic soon). This means that applications can react real-time to data changes, enabling the creation of highly responsive and dynamic applications.
Cloud Functions 2nd generation
Cloud Functions allow developers to create serverless applications that run in response to various cloud events. All this without having to worry about infrastructure, docker, packaging your code, etc. Google Cloud takes care of all the boilerplate for you.
For the code logic to dispatch the expense report to a Slack channel, we wanted to use an engine that matches the simplicity of our code — we found it with Cloud Functions 2nd gen. We develop our code locally, test it with the functions framework and then deploy it through a fully automated CI/CD pipeline that will test the code and then trigger a terraform plan for an end user to review.
We use terraform to deploy Google Cloud resources but we keep the code logic in a separate repository. Terraform only contains the resource deployment with a reference to the source code located as zip file on GCS bucket. This reference is a version tag that consists of a terraform variable that is automatically updated by the CI/CD pipeline of the source code. This makes the development loop fully automated, versioned and safe at the same time as the CI/CD will include various python tests and the deployment through terraform requires a human in the loop to review and apply it.
The CI/CD and deployment of this Cloud Function is depicted in the following architecture:

Last but not least, we are deploying different Cloud Functions for the two use cases we are treating (daily and monthly expense reports). But both Cloud Functions use the same codebase, the only difference is in the entrypoint. This allows us to decouple neatly between different use cases while keeping the codebase unique.
Airflow
Airflow is a powerful tool to automating and scheduling tasks, allowing for the efficient management of data pipelines. In our use case, we are using Airflow to perform a variety of tasks related to data quality, data transformation, and data distribution.
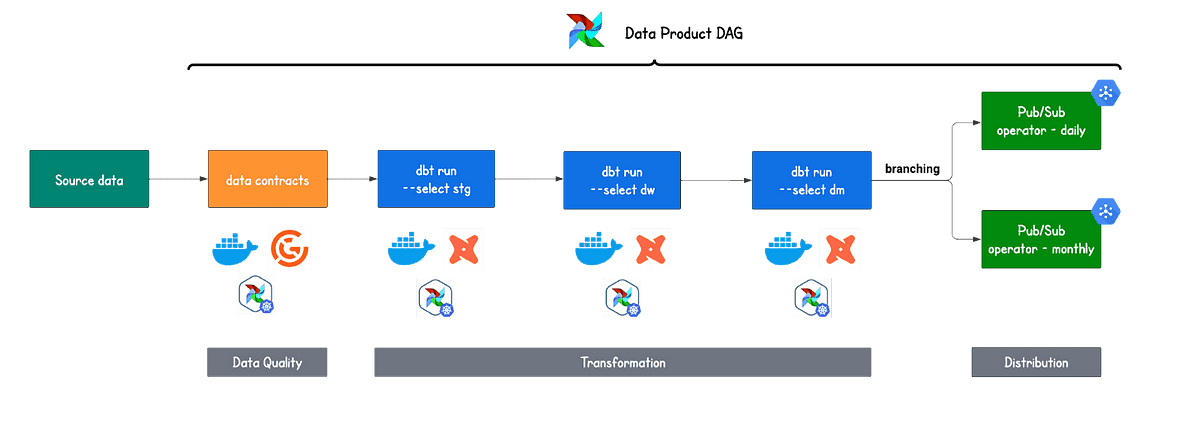
Data quality is an important aspect of data pipeline management. At Astrafy, we are using Great Expectations to create data contracts, which allows us to validate our data and ensure it meets our expectations. Great Expectations itself has a functionality that sends reports to our Slack channel, keeping us informed of any issues with our data. This allows us to easily monitor the quality of our data and ensure that it is of high quality for downstream processes.
Data transformation is a critical step in preparing our data for analysis. With Airflow, we are able to schedule the transformation of raw data using dbt from data source into clean and curated datamart tables. This approach allows us to scale our data processing as needed, ensuring that we can handle increasing volumes of data without sacrificing the quality or accuracy of our analysis.
Before triggering the Pub/Sub operator, we use the BranchPythonOperator in Airflow to conditionally execute certain tasks based on a specific condition. This creates a more flexible and robust workflow that can handle different scenarios. In our use case we want two report:
a monthly expense report, which is generated on the first day of each month.
a daily expense report which is generated every day in the afternoon.
The PubSubPublishMessageOperator publishes a message to the GCP Pub/Sub service, triggering the GCP Cloud Function. The Cloud Function retrieves the latest expenses data from BigQuery, parses it, and sends a summary report to a Slack channel.
Terraform
As previously mentioned, we deploy all Google Cloud resources through terraform. This allows us to know at any time what is being deployed and to avoid users to deploy manually resources that we then lose track of. In this architecture, we have deployed the following resources via terraform:
Google Cloud datasets for the FinOps data product
Google Cloud IAM bindings for access to the data by end users and service accounts
Pub/Sub topic
Google Cloud Function 2nd generation
We also deployed Airflow on a GKE cluster and we have written a detailed article on this deployment; you can find it here.
It is worth noting that the source code for the Cloud Functions is kept separate from the terraform code that deploys the Cloud Functions. This is important for “separation of concerns”; terraform deploys infra and source code of a Cloud Function should not be mixed within infra code.
ChatOps with Slack
As many companies, we use slack as our messaging tool for internal communication but more importantly we use slack as a command centre for notifications from our different applications and for informing stakeholders with insights. That’s this latter user case that we covered in this article. As slack is one of the few applications that everyone at Astrafy has open at any time, the best way to convey a message is through slack. Those expense reports are seen on a daily basis by all of us because those are accessible through a slack channel that everyone has joined (we recommend creating a channel named “finops”).
Interacting with slack is quite easy due to their very well documented API and client libraries. We used the python-slack-sdk library to interact with slack from our Cloud Function. To format and make the slack message appealing, we recommend using the interactive block kit builder. It allows you to iterate quickly on the design of your message and you can then use the json in your source code.
Monitoring
“If something can go wrong, it will.” While our architecture has various tests in place, unexpected errors can always happen and that’s why we have monitoring in place in the following two key components of our architecture:
Airflow: monitoring of the gke cluster that hosts Airflow as well as monitoring of the DAGs and tasks within the DAGs.
Cloud Function: monitoring of the eventual errors of the Cloud Functions.
This monitoring is done through Google Cloud operations that sends emails and slack notifications if an alert is fired. This proactive monitoring makes sure we are on top of things as soon as something breaks.
On top of this Ops monitoring, we also have data monitoring through data contracts (first task in our Airlfow DAGs) where we check the integrity of the data. As aforementioned in the Airflow section, we leverage Great Expectations for this and have a dozen tests to check on a daily basis the amount of new data, outliers in some fields, etc.
Conclusion
Nowadays tons of data gets piled up in analytical databases and only a few percent of this data gets used for insights. This pattern follows the pareto principle where 10–20% of the data drives the business. There needs to be a shift into first thinking about the use case and what we want from the data and then getting it and transforming it. That’s our mindset at Astrafy where we define clear data products with business use cases that will derive from those. This design phase takes as much time as the implementation phase but allows us to keep a clear focus and to bring added value to our various stakeholders.
This expense report is just one of many use cases we foster from our FinOps data product and in subsequent articles, we will go over other generic Google Cloud use cases that you can easily implement at your company.
Those expense summary reports inform the business about cloud expenses in detail and this is the foundation of FinOps — measure and inform. Once you have automated visibility on your costs, then only you can act on those.
Stay tuned for our next article on a monitoring data product to get full visibility on your analytical transformations.
If you enjoyed reading this article, stay tuned as more articles will come in the coming weeks on exciting data solutions we build on top of generic Google Cloud data. Follow Astrafy on LinkedIn to be notified for the next article ;).
If you are looking for support on Data Stack or Google Cloud solutions, feel free to reach out to us at sales@astrafy.io.
Written by

Charles Verleyen
CEO & Lead Architect



