Blog
Dataform and Terraform: Automate SQL pipelines in production
Reading time.
1 min
Wrtitten by
Alejandro de la Cruz López
Google Cloud
Data Engineering
Infra & DataOps

What is Dataform
Dataform, in a nutshell, allows you to orchestrate SQL workflows. This helps transform raw data into reliable datasets for analytics. It also provides a collaborative platform for managing SQL workflows, testing data quality, and documenting datasets.
Google bought Dataform in 2020 to integrate it with BigQuery, and since then they have been working to develop it entirely for GCP. Their latest big release 3.0 announced that Dataform will no longer support other data warehouses or databases apart from BigQuery, becoming an integrated part of the GCP platform. You can access it directly from the BigQuery service.
Its integration with BigQuery makes Dataform compelling over other options in the market for companies that already have their data stored in BigQuery.
How should I orchestrate Dataform
If you are using dbt, you either need an orchestrator, such as Airflow, or dbt cloud to execute the queries in your dbt models. This is a main concern since having your own infrastructure implies spending time and money on it. On the other hand, dbt cloud is quite expensive. Therefore, neither option is optimal.
On the contrary, Dataform is integrated into GCP (and it’s free). Therefore, it enables direct access to GCP orchestration tools. Dataform has an orchestration functionality, which allows you to orchestrate your Dataform pipelines. However, this feature is not customizable enough for most cases for the following reason: it is not possible to run the pipelines with dynamic variables such as date.
In the real world, most of the pipelines are incremental, since every day you are ingesting the new data from your sources. The straightforward approach is to use CURRENT_DATE() in the SQL query. However, if any run fails, re-executing it will mean running a different query since the date may be different. The recommended approach is to use a variable such as date. Then, when re-executing, it will ingest the data for the date provided as a variable and not a relative time related to the current date.
For this reason, using automated workflows is not suitable in most cases. However, for those projects that do not need to use dynamic variables, this approach has advantages:
Really simple and integrated inside Dataform
Scheduled queries on a cron interval
Can be fully automated with IaC (Terraform)
For a simple project, this is all we need, and having orchestration that easily is really convenient.
Other options to orchestrate Dataform are Airflow (or any other orchestrator) and Google Workflows. The first option is ideal but, as discussed before, it is time and cost expensive. The second one is the one we recommend and it will be explained in this article.
Orchestrating Dataform
There are several ways to execute Dataform. You can check a very informative comparison below from the article Mastering Dataform Execution in GCP: A Practical Guide with CI/CD Example.
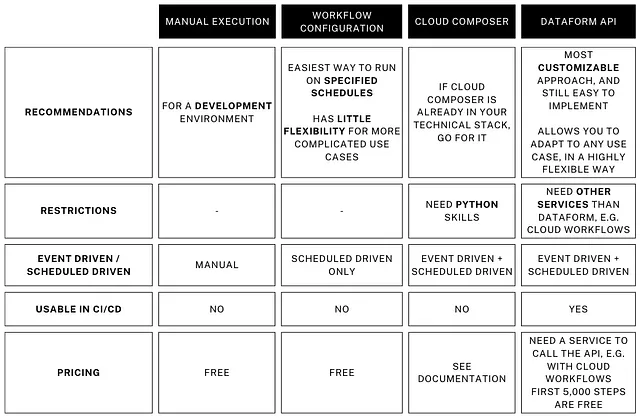
Possibilities to run Dataform
Ideally, the best approach to follow is using an orchestrator. This is because Dataform does not provide a UI where you can see every day’s run with its results. This complicates debugging on which dates the model runs and can lead to issues. It also provides functionality to run custom code for other functionalities needed before, between, or after your SQL pipelines.
Yet, we recommend leveraging its integration with GCP and orchestrating it using Google Workflows. This allows to automate the whole deployment with Terraform with very few simple scripts. Besides, Google provides its documentation and an already-made workflow for this. This solution proposes a balance between simplicity, cost, features, and maintainability. Consequently, here is the architecture.

Production Dataform Architecture
Demo: FinOps data product
To show the Dataform production environment, we will build a simple data product related to FinOps. This will consist of two models and a source. The source will be Google Cloud billing data table that contains the price for all used resources in our Google Cloud organization. You can check the code for the Dataform repository here.

Bootstrapping Dataform repository
You can check the official guidelines for the CLI here.
Before installing the Dataform CLI, install NPM.
Make sure to be inside the git folder you have created in your repository client (GitLab, GitHub, etc.)
This will create a folder structure with workflow_settings.yaml file such as the following.
You can remove the default dataset entry to use the one you will set in your models
Set the project you want to use to store your models
Set the location of your BigQuery datasets
Set the
defaultAssertionDatasetto a dataset where you want to store your tests. Example:bqdts_finops_tests
The final structure is the following. The folders dm, int, sources, and stg are created manually to host there the models for each of the layers.

We will then build int_billing_data.sqlx and net_cost_grouped.sqlx.
Declaring sources and models
We declare the source as such.
Then, we build the models. Here are a few best practices we recommend:
Set the tag of the stage (int, stg, dm) so that it is possible to run a stage using the tag.
Set the type. It can be incremental, table, or view.
Set the schema where to write this model
Set the partition and clustering if needed
Set the assertions, these are tests. You can see the documentation here.
In the
pre_operations, you need to remove the current partition to have a similar behavior as dbt for incremental models. First, delete the partition you are inserting so that you don’t repeat data in your final table.
Here is an example of the model int_billing_data.sqlx. The final model net_cost_grouped.sqlx uses the same columns but adds up cost and discount to get the net_cost. This way we have a simple production-ready finops data product.
Then, we are ready to deploy our infrastructure in Google Cloud to run our data product.
Deploying Dataform with Terraform
The repository contains a top-level folder in which shared resources will be created and a module inside the folder dataform. This module will contain all resources that need to be deployed per environment (dev, stg, prd). You can find all the code shown in this section in the following repository.
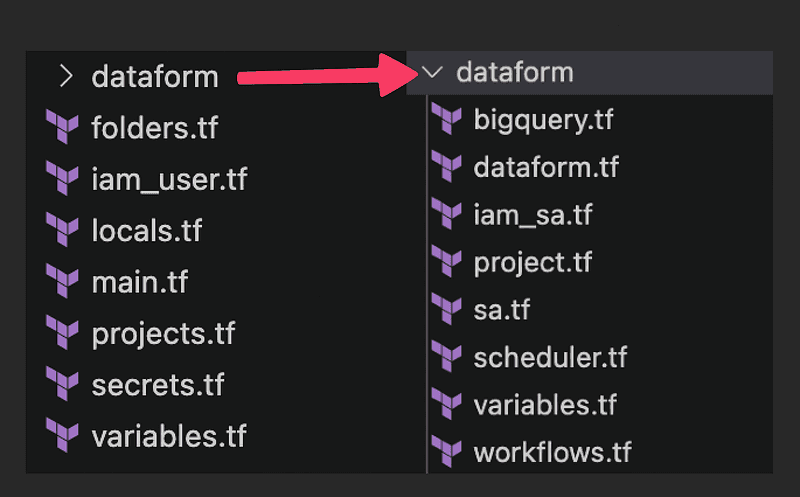
Terraform repository structure
To build the desired architecture, we need the following components.
1. Project and folder infrastructure
Starting with the basics, we will create a folder with three projects. The operations, development, and production project. Ideally we would also have a staging project, but we will omit it for this demo. The top folder and operations project are created in the top-level folder. The development and production projects are created inside the dataform module.

Project and folder structure
2. External repository
Dataform connects with an external repository to read the queries and other Dataform metadata. You can read the official documentation here. In a nutshell, you will need a key to access the repository in a secret. This is done in the ops project.
3. BigQuery datasets
If they are not yet provisioned, you will need all the BigQuery datasets to create the tables with Dataform. Dataform creates the datasets by itself, but it is a best practice to do it with Terraform. We suggest a landing zone (lz), staging (stg), intermediate (int), and data mart (dm) strategy. A dataset for Dataform tests is also needed.
4. Service accounts & IAM
You need two service accounts for dev, and two for production. One is responsible for executing the Google Workflow that will then trigger the Dataform pipeline. The second one is responsible for triggering the Dataform pipeline.
The permissions needed are the following.
Secret accessor to the Dataform default SA to access the secret for the repository
SA token creator to the Dataform default SA to the Dataform runner SA, so that it can run workflows
BigQuery jobUser and DataEditor to the Dataform runner SA
Workflows invoker, and Dataform editor to the Workflow runner SA
SA token creator to the Workflow runner SA to the Dataform runner SA so that the workflow can trigger the dataform pipeline
5. Dataform repository
This resource is connected to the repository where your SQL files will be stored. Also, you will be able to see this repository the Dataform UI with its runs and the result of each.
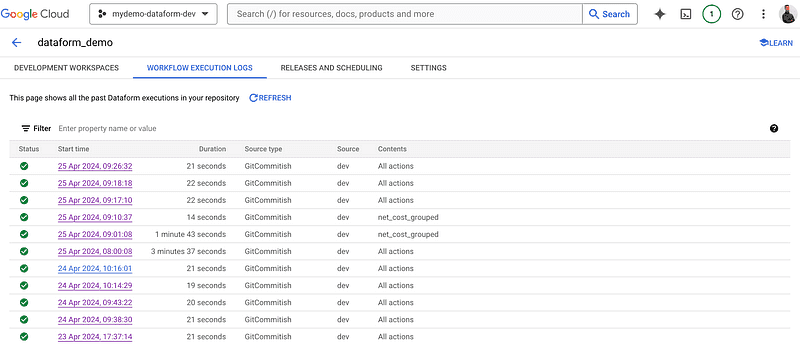
Dataform UI for workflow execution logs
6. Workflow that triggers Dataform
The date variable is a Dataform variable used to run the pipeline in an incremental model. This way, the SQL queries know which data they need to retrieve and process. It defaults to use the last day in format YYYY-MM-DD
All the variables in the init step can be modified when triggering the workflow. There is a description of each of them:
date: Date to use in your incremental queries
project_id: Overwrites the default project.
git_commitish: Selects the git branch to use.
dataform_tags: Runs only a selection of tags.
dataform_targets: Runs only a selection of actions (models).
include_dependencies / include_dependents: Runs dependencies/dependents actions of selected tags/actions.
dataform_service_account: Dataform will perform all operations on BigQuery using this service account. If an empty string, default Dataform SA specified in your repository settings is used.
fully_refresh_incremental_tables: Recreates from scratch incremental tables.
wait_for_dataform_status_check: If true, the workflow will wait until Dataform transformations finish and return an error if Dataform does as well. If false, it will send the request to Dataform to execute the transformations and return success independently of Dataform’s result.
compile_only: Compile the Dataform code and do not execute it. Can be useful in a CI/CD pipeline to check there is no Dataform compilation errors before applying something.
Here’s an overview of what each step of the pipeline does:
createCompilationResult: This initial step compiles the Dataform source code from the designated Git branch.
earlyStopBeforeDataformWorkflowInvocation: If any errors are detected during the compilation phase, the workflow halts, displaying the encountered errors. Also, if
compile_onlyis set to true, the workflow stops here.createWorkflowInvocation: Involves triggering the compiled Dataform code for invocation.
earlyStopBeforeDataformStatusCheck: If you do not care about the Dataform transformation outputs, this step will stop the workflow execution before the status check.
getInvocationResult: This step retrieves the status of the executed Dataform invocation. The possible results include “RUNNING”, “SUCCEEDED”, “FAILED”, or “CANCELLED”.
waitForResult + checkInvocationResult: Continuously monitors the Dataform status obtained from the previous step. It iterates every 10 seconds until the status changes from “RUNNING”. Finally, it displays the definitive state of the Dataform process.
7. Scheduler
In order to run it automatically, we trigger the workflow every day at 8 am.
Infrastructure deployed
Then, we have a Cloud scheduler that triggers the Workflow pipeline once a day at 8:00, which we see below (the first one was a test).

Google Workflow that triggers Dataform
The Dataform workflow is triggered right after the workflow.

Dataform workflow execution logs
We see the tables populated in the BigQuery production project.
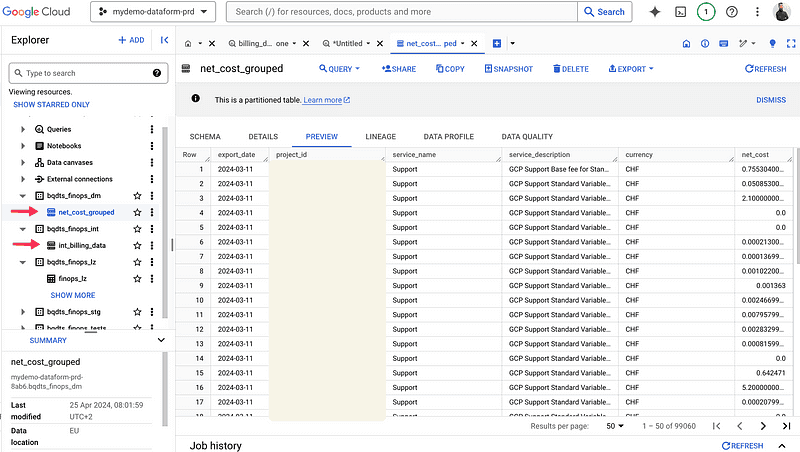
BigQuery production project
Conclusion
As Dataform is integrated into Google Cloud, it is really easy to use it across different services, which makes it a great fit for organizations having data in BigQuery. Automating its deployment with Terraform is fairly easy as we have seen, and its maintenance requires little to no time thanks to its integrations.
While there are other tools in the market that perform similar tasks, it is definitively a good idea to select Dataform as the choice for SQL orchestrators in Google Cloud.
Thank you
If you enjoyed reading this article, stay tuned as we regularly publish technical articles on data stack technologies, concepts, and how to put it all together to have a smooth flow of data end to end. Follow Astrafy on LinkedIn to be notified of the next article.
If you are looking for support on your Google Cloud data & ML use cases, feel free to reach out to us at sales@astrafy.io.
Written by

Alejandro de la Cruz López
Lead AI Engineer



