Blog
dbt at scale on Google Cloud - Part 3
Reading time.
4 min
Wrtitten by
Charles Verleyen
Google Cloud
Analytics Engineering
Data Engineering

It does not matter how slowly you go as long as you do not stop.
In this part 3 of “dbt at scale on Google Cloud”, we will deep dive into the following topics:
Orchestration with Cloud Composer
DataOps
dbt selectors
dbt package
Documentation
Monitoring
Project Management
Orchestration with Cloud Composer
In part 1 of this article, we introduced the following architecture to orchestrate a data product from ingestion to distribution:

Various excellent open-source tools exist to orchestrate those operations (Dagster, Prefect, etc.) but our recommendation goes with Airflow and its fully managed flavour via Cloud Composer on Google Cloud. You will pay a premium for the fully managed service but you will be up and running with an excellent orchestrator in a matter of minutes. As always, deploy your resource via Terraform and you have to use the google_composer_environment. Deployment of Cloud Composer in fully private mode with a shared VPC configuration requires some more set up and we plan to write a detailed article together with a repository to detail this set up.
Once your Cloud Composer instance is up and running, you can start uploading Airflow python files in the Cloud Composer bucket and you can then visualise those DAGs via the UI. As we will see in the DataOps section, upload of the DAGs should only be done via an automated CI tool.
A DAG has to be seen as a self-contained data product that includes all the stages from ingestion until distribution of the data. In the architecture above you can see that the first stage refers to ingestion and it might be triggering an Airbyte sync or triggering a Cloud Function that ingest new data.
In order for your data eco-system to scale properly and to split the orchestration from the execution of the tasks, stages should use the “GKEStartPodOperator” and spin up pods on a different cluster. This will ensure that the Airflow cluster never gets overwhelmed and is only busy scheduling tasks. The following architecture describes the interaction between the two clusters:

The following snippet is an example this operator for a dbt run operation:

This stage will run the image “dbt” located on the artifact registry project with the following arguments:
[‘run’, ‘target_gke’, ‘finance_stg’, ‘full-refresh’, ‘{{ run_id }}’, ‘{{ ts }}’]
The docker image is as follows:
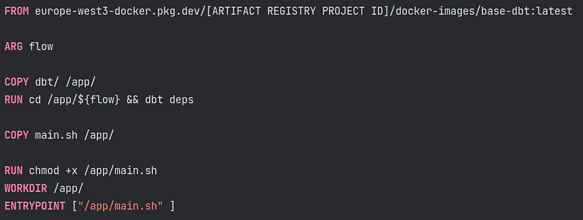
It is a multi-layered docker image and the base layer is just an image with dbt installed on it. This base dbt image is quite static (changed only when dbt version is upgraded) and this makes the build of this Dockerfile quite fast as the only steps are copying files from the repository and installing the packages. There is one build per data product (i.e. per dbt project) and each data product has therefore its docker image with its own tags (more on this in the DataOps section).
The “main.sh” file is just a small shell abstraction that has the logic to run the different dbt commands. For instance, the commands from the operator above will translate into this dbt command:
dbt run --vars '{"dag_id": “${run_id}”, "dag_ts": “${ts}"} --target target_gke --selector finance_stg --profiles-dir=/app --full-refresh
The docker image has the entire dbt codebase and will therefore run this command successfully.
We are passing the following Airlfow macro reference to dbt:
the run_id of the current DAG run
the execution_date of the DAG
Those two variables serve as precious metadata for monitoring purposes and to link the data materialised to a specific dag run.
In the operator above we have specified a kubernetes service account to be used to run this task. You need to activate workload identity in your cluster in order to permit workloads in your GKE clusters to impersonate Identity and Access Management (IAM) service accounts to access Google Cloud services. To achieve this, you first need to create a Kubernetes service account and then give permission to this service account to impersonate your google cloud service account that has the necessary permission to run your dbt operations:
Resource to create Kubernetes service account
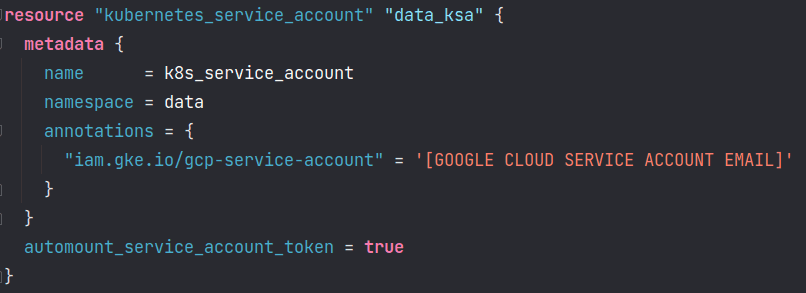
2. IAM binding for impersonation / workload identity:
Once you have applied those two resources, your GKEStartPodOperator that has a Kubernetes service account defined will be able to impersonate a Google Cloud service account and use all its underlying permissions. Workload identity allows you to use a service account without having to create a service account key.
Last but not least regarding the operator, it is using ‘nodeAffinity’. Node affinity ensures that the pods will be scheduled on a specific node pool. You might have various node pools on your cluster (one for airbyte, one for Lightdash, one for your dbt workloads, etc.) and it is therefore important to schedule your workloads on their respective node pools.
As far as the DAG schedule is concerned, we recommend having two DAGs per data product:
One DAG that has no schedule (i.e. can only be triggered manually) and that does a full refresh of your data
One DAG that has a schedule with a certain frequency (daily, hourly, etc.) and that runs incremental loads of your data.
Your dbt code must have the logic to accommodate for incremental load for your DAGs to run at fast pace and for your costs to be limited at each run. You achieve this by materialising your models with the incremental type. You then put your logic for loading the incremental data by leveraging the “is_incremental()” macro.
The last operators of your DAG should have the following objectives:
Notify stakeholders about new data in the datamarts they use. This can be achieved by slack or email notifications.
Notify external stakeholders to trigger downstream operations. This can be achieved via a Pub/Sub operator that will send a message to a topic on the stakeholder project. The stakeholder will then use this message to automate the trigger of some operations.
Trigger a ML model. If you are using Vertex AI for your ML operations, this can be achieved by using the Airflow Vertex AI operators.
DataOps
Automation is key and if something can be automated, then it must be automated. This section will focus on the continuous integration pipeline that runs various stages. Hereafter is an architecture of the main stages that you recommend to run in a CI pipeline upon merge request and after each merge in the master branch:

It is important to note that there exists a multitude of CI tools in the market. We have no specific opinion on the tools as all mainstream tools allow you more or less to do the same. That being said, we personally use Gitlab CI and are very satisfied with its functionalities.
We will now deep dive in the different CI stages and those are split in three main blocks:
Code Quality/Consistency checks: this block consists of checks that ensures that commits from your data team complies with the style guide that you have established in your department. To ease the job of your engineers, those checks can be set up as pre-commit hooks; your engineers can then have direct feedback before they commit and their commits will have less likelihood to fail those checks in the CI pipeline.
SQLFluff checks: SQLFluff is an extensible and modular linter designed to help you write good SQL and catch errors and bad SQL before it hits your codebase. You can configure SQLFluff rules via a “.sqlfluff” at the root of your repository. By default, core rules are enabled but you can then customise or disable some of those rules. The following setup is what we use in our projects:
rules = L001,L003,L004,L005,L006,L007,L008,L010,L011,L012,L014,L015,L017,L018,L021,L022,L023,L025,L027,L028,L030,L035,L036,L037,L039,L040,L041,L042,L045,L046,L048,L051,L055
SQLFluff also has a utility function that can fix SQL (sqlfluff-fix). Developers can use it locally to format their queries before committing but this utility should not be used within a pipeline as this feature is not mature enough and could lead to undesired effects.
When integrating SQLFluff in your CI tool, use it with the “diff-quality” parameter. This will avoid that a merge request gets overwhelmed by failed quality checks from other files that were not touched by this merge request.dbt quality checks: Those are checks that ensure that the dbt code complies with the style guide in place. A curated list of dbt tests can be found on this repository. In case you need to add some tests, you can take inspiration from the code in this repository as it is well structured and documented. While having a lot of checks ensures consistency and quality, it can also slow down development and increase frustration within your dev team. You need to find a good trade-off between those checks and development velocity for your engineers. This balance evolves over time; you might start with a few mandatory checks and when your project gets to a certain maturity with an increasing number of developers, you can then raise the bar for this quantity of checks. Here are some checks that you should set as mandatory in our opinion:
- check-column-desc-are-same
- check-column-name-contract
- check-model-columns-have-desc
- check-model-has-all-columns
- check-model-has-description
- check-model-name-contract
- check-macro-has-description:
- check-macro-arguments-have-desc
The github repository also contains a very valuable macro that can generate model properties files.
Compilation tests and SQL unit tests:This block of three stages makes sure your code compiles and will not make dbt or Airflow crash.
dbt compile: if it can’t compile, it can’t run. You expect your engineers to have run and iterated locally on the changes they are pushing. But a golden rule is “better be safe than sorry”. This stage will execute a “dbt compile” with and without the “full refresh” flag.
dbt unit tests: As explained in part 2 of this article, unit tests are there to check the logic of your SQL code. This logic needs to be tested only when code changes as opposed to data integrity tests that need to be tested at each DAG run. Those unit tests will put in place dummy data via dbt seeds and end results after the SQL transformations need to match expected results. If not, the pipeline will fail.
Test Airflow DAGs: Many tests can be implemented for Airflow DAGs (see this section). We recommend putting at least the test that ensures that the DAG compiles. If this test passes, it means your DAG will appear in the UI and can be triggered. We add also the following tests in this stage:
- Check that the DAG id abides to a certain naming convention
- Check that the DAG contains at least one ingestion stage, one data integrity stage and one dbt stage
- Check that the ingestion stage executes before the data integrity stage and that the data integrity stage executes before the dbt stage(s).
Build artifacts: Once the pipeline reaches this block, it means the code is safe and sound and artifacts are ready to be built out of it. Three stages run in parallel in this block:
Build Docker image: The docker image is the artifact that is used in the Airflow DAG via the GKEStartPodOperator. It contains all the repository code and is tagged based on the git tag of the merge request. Each data product has its own docker image and it is the responsibility of each data product owner to notify other data product owners in case they introduce a breaking change in their models that will impact your data product (for instance removing a column, etc.).
Upload DAG to Cloud Composer bucket: This stage uploads the DAG to the GCS bucket linked to Cloud Composer. Once the DAG is uploaded, it is then available in the UI to be activated and scheduled. We recommend to set the following two parameters in your main DAG config:
- catchup=False
- is_paused_upon_creation=True
The first one ensures your DAG is not going to run in the past and start backfilling data. There are use cases for this but you probably don’t need this until you reach a certain maturity (check this article for explanation of those backfilling concepts). The second parameter ensures your DAG is paused upon creation and obliges your data product owner to go to the UI and activate it manually the first time (it is a valuable safeguard).Update dbt docs: This stage uploads the dbt docs artifacts to a GCS bucket that is then served by App Engine. More detail on this in the “Documentation” section.
If you get this pipeline fully implemented, you can be confident that your merge requests won’t break anything and that your code will comply with your style guide. We are currently investigating and testing Datafold Data Diff feature as this could add an extra confidence layer in the downstream changes a dbt model would generate. We will write a dedicated article on this but it looks very promising. An open-source version of this utility is available on this github repository.
dbt packages
As per dbt website:
Software engineers frequently modularize code into libraries. These libraries help programmers operate with leverage: they can spend more time focusing on their unique business logic, and less time implementing code that someone else has already spent the time perfecting.
In dbt, libraries like these are called packages. dbt’s packages are so powerful because so many of the analytic problems we encountered are shared across organisations.
In our opinion, dbt packages are what make dbt so popular (and open-source technologies in general); you simply don’t need to reinvent the wheel. Chances are someone has already built datamart models for Mailchimp or Google Analytics data; it might not be exactly what you are looking for but it will give you a head start. Packages are very simple to use as you only need to set them in the “packages.yml” file at the root of your dbt project and then run “dbt deps” to install those packages.
This github repository contains a list of curated dbt packages (on top of many other useful links). Here are our favourite ones from this curated list:
fzf-dbt: Not a package but a terminal utility that will help you search your dbt models. Useful when you start having 100+ models.
vscode-dbt-power-user: Not a package but a must-have extension if you are using Visual Studio Code.
fal: allows you to run Python scripts directly from your dbt project.
dbt_project_evaluator: this package makes an audit of your dbt project against dbt best-practices.
dbt_profiler: this package allows you to get quick data profiling from your table.
dbt_utils: this package is a must-have and contains official utilities macros.
re_data: this package gives you full observability on your data and notifies you if anything abnormal surges.
dbt-erdiagram-generator: This package generates ERD files from your dbt models.
dbt-coverage: One-stop-shop for docs and test coverage of dbt projects.
dbt-invoke:is a CLI (built with Invoke) for creating, updating, and deleting dbt property files.
dbt-unit-testing: contains macros to support unit testing.
dbt_model_usage: lets you know whether your models are still relevant to your users.
Bottom line is that you should always be on the lookout for packages that meet your different use cases. Using packages relieves your team from maintaining additional code and is a considerable gain of time.
Selectors
dbt’s node selection syntax makes it possible to run only specific resources in a given invocation of dbt. While this is convenient and allows you to target any kind of models, those selections remain within your command line calls. YAML selectors allows you to write resource selectors in YAML, save them with a human-friendly name, and reference them using the — selector flag. These enable intricate, layered model selection and can eliminate complicated tagging mechanisms and improve the legibility of the project configuration.
We highly encourage you to write your selectors in a “selectors.yml” file. This will help your future self and all your colleagues to have a centralised place to define and understand the selectors in place. The advantages are as follows:
Legibility: complex selection criteria are composed of dictionaries and arrays
Version control: selector definitions are stored in the same git repository as the dbt project
Reusability: selectors can be referenced in multiple job definitions, and their definitions are extensible (via YAML anchors)
When running dbt commands, you can then simply invoke those selectors by setting the flag “ — selector [SELECTOR NAME]”.
Documentation
dbt provides a way to generate documentation for your dbt project and render it as a website. The documentation for your project includes:
Information about your project: including model code, a DAG of your project, any tests you have added to a column, and more.
Information about your data warehouse: including column data types, and table sizes. This information is generated by running queries against the information schema.
Documentation can easily be generated by running the command “dbt docs generate” and then rendered by running “dbt docs serve”. The first command will generate the html artifacts and the second command will render those documents on your localhost. Few drawbacks need to be tackled to have this documentation consistent and industrialised.
First of all, part 2 of this article recommended a repository structure where you end up with one dbt project per data product. This means you will have documentation artifacts per data product and not a global documentation. This can be solved easily by creating a dedicated dbt project that imports all the other dbt projects within its packages.yml file. You can then run “dbt deps” followed by “dbt docs generate” and “dbt docs serve” and you will end up with one nice dbt data catalogue for all your data products.
The second problem is that the command “dbt serve” renders the HTML files locally. In production, you need this data catalogue to be widely accessible and this can be easily done by uploading the artifacts generated by “dbt docs generate” on a GCS bucket. An App Engine standard service is then used as a GCS proxy and web server to host this dbt data catalogue. Having App Engine as the engine comes with the nice feature of having “Identity-Aware Proxy” out of the box. This will make your security team happy as you can apply fine-grained control on who can access your data catalogue. Hereafter is representation of this architecture:

While dbt provides a simple data catalogue, it is 100% static and chances are that your company already has a professional data catalogue solution or will want to implement one. In that case you should select a data catalogue solution that has an integration with dbt. Your model properties have a lot of information and those should be fetched within your data catalogue.
Monitoring
Having robust monitoring allows you to be proactive to problems instead of reacting to them as a firefighter. There is nothing worse than having your stakeholders notifying you about a data quality issue or stale data. dbt, its many packages and Google Cloud Operations suite allows you to be in full control of your data ecosystem. We will describe various level of monitoring you can achieve:
A high-level monitoring lies at the Airflow DAG level. You want to be notified as soon as one of your DAG fails. We could implement the on_failure_callback with the slack python client but we recommend leveraging Google Cloud Operations suite. This has the benefit that you decouple monitoring from your Airlfow DAG code. The procedure is as follows to set up this monitoring:
1. Create a logging metric via terraform (google_logging_metric resource). You catch DAG failure with those two parameters:
filter = “resource.type=\”cloud_composer_environment\” AND textPayload =~ (\”Marking run\” AND \”DagRun\” AND \”failed\”)”
label_extractors = {“dag_run” = “REGEXP_EXTRACT(textPayload, \”DagRun (\\\\_+|.*) @\”)”}
2. Create a monitoring alert via terraform (google_monitoring_alert_policy resource) and referencing the logging metric previously created. For the notification channel, you can reference either slack, emails, etc. directly or a Pub/Sub topic. We recommend using a Pub/Sub topic as you can then apply custom logic to those messages. We have implemented a monitoring factory in Cloud Run that listens to this topic and dispatches those alerts to different messaging tools as well as journaling those alerts in BigQuery.
Architecture of this setup is as follows:

The Datastore serves as a configuration store to know how to dispatch the alerts for each data product. This data is stored as a meta block within the “dbt_project.yml” of each data product and uploaded to Datastore during the CI.
Monitoring of your dbt models so you can answer the following questions:
- Why isn’t my model up to date?
- How long did my model take to run?
- When is the last time my model ran?
- Is my data accurate? Did my tests pass?
- Why are my models taking so long to build?
This article gives in-depth details on this implementation but this is compatible and only fully tested for snowflake as of now. You can follow this repository to be first in line once it is compatible and tested with BigQuery. In the meantime, you can get almost the same results by implementing the solution of this article. Logic behind this implementation is to log the invocation id of each dbt run and then join this data to the BigQuery INFORMATION_SCHEMA dataset.
You can also leverage slack notifications at the dbt model level by using the fal library mentioned above.
BigQuery audit logs: As all your data will reside in BigQuery and will be processed by BigQuery, it is of major importance to be able to audit all the logs generated by BigQuery. You can achieve this by creating a log sink with a BigQuery dataset as the destination for all the BigQuery logs. This will export all your BigQuery logs to a BigQuery table and you can then run queries on this data to get the insights you want. This repository contains a sample of useful queries and this article will guide you on how to build a Data Studio dashboard on top of your BigQuery logs (you will need to adapt the query to accommodate for the v2 of the logs though).
The logs contain all the information you can imagine and you can therefore get the insights you want by manipulating the logs data; it is just SQL. For instance you could get a list of users that tried to query a protected table.Data docs with great expectation: Last but certainly not least, you need to report on the integrity of your data. As detailed in part 2 of this article, we recommend using Great Expectations mainly because of its “data docs” feature. Similarly as dbt docs, those data docs are static html files that we can serve via an App Engine service. It contains in-depth details about the tests that have been performed and their results. Each Great Expectation suite can contain an action to dispatch a slack notification.
If you successfully implement those different monitoring features, you will achieve a high level of observability on your data products. This in turn will allow you to pinpoint the area for improvements and steer your work on the right tasks.
Project Management
We end this long article with a non-technical section. This section however is a key factor in the implementation success of this modern data stack. We have seen too many times lack of proper project management leading to failure of data projects. There is still a wide gap between business people and technical people when undergoing such projects. It is critical to have a product owner and/or scrum master that is technical and can liaise properly with the business to manage expectations. Results and consistency can take months to be in place due to the onboarding of those new technologies and set up of all this ecosystem. The time factor does not lie in the technologies that can be deployed quickly but more in the change management culture that needs to take place.
Management should understand that modern data stack technologies are ever-evolving at the moment and that refactoring and changing directions are common practices and need to be embraced. Agility in failing is key and as the adage says “Fail fast and learn fast”. It is the role of the management to put in place a culture where blaming is absent and where failing is part of the process.
High rate of employee turnover is a symptom of a toxic culture and a direct consequence of failing to implement a modern data stack. Keeping your employees in such a dynamic environment where domain knowledge is key and shortage of talents keeps on growing is fundamental. Great stack won’t lead you anywhere if you don’t have the right people to configure and execute it.
Goal of this article was on the technical aspect of setting up a modern data stack on Google Cloud with dbt at its core but we could not finish without mentioning the importance of having a solid culture with a sound management team. We plan to write dedicated articles on the non-technical aspects of implementing a modern data stack; stay tuned ;).
We really hope you enjoyed reading this article and that it has enlightened you in some ways to improve or jump-start your modern data stack implementation.
If you are looking for support on Data Stack or Google Cloud solutions, feel free to reach out to us at sales@astrafy.io.
Written by

Charles Verleyen
CEO & Lead Architect



