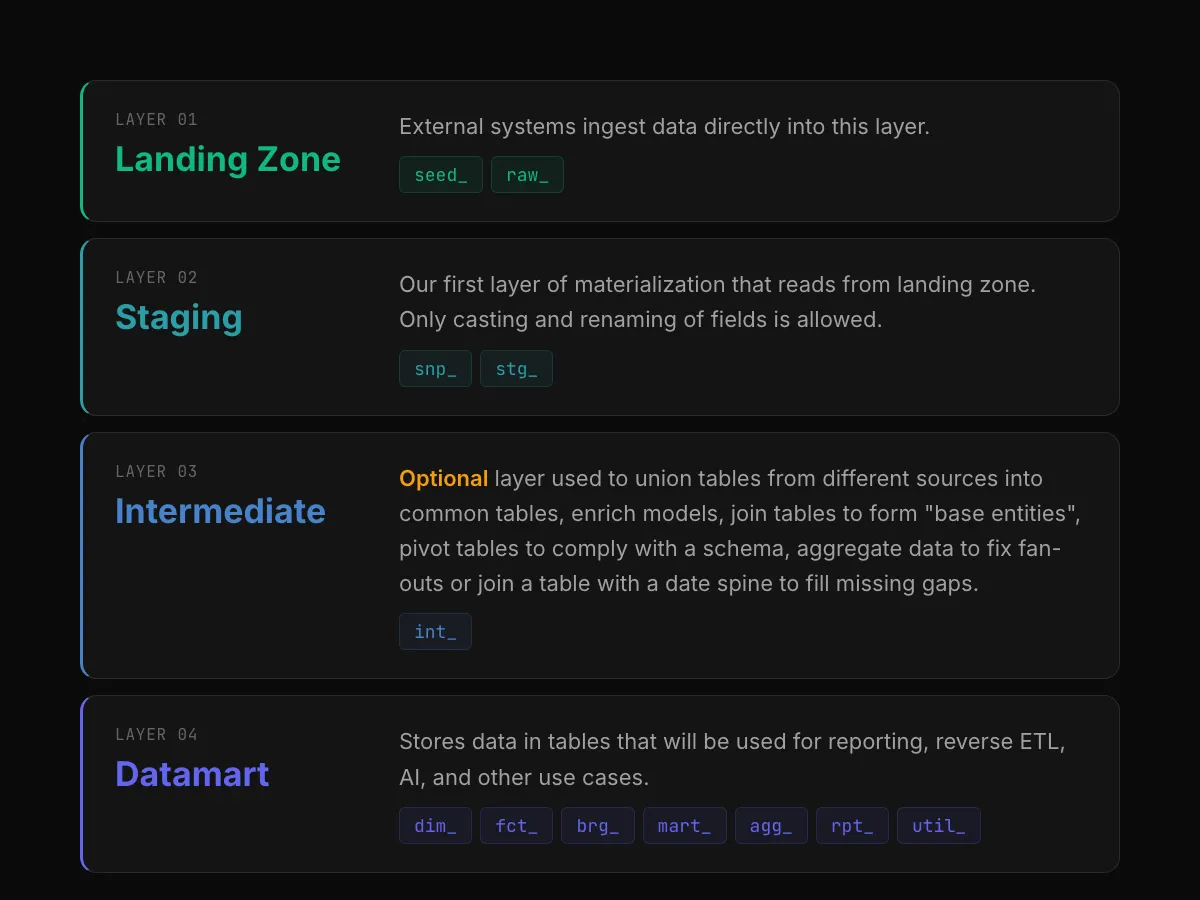
Introduction
In the current world of data, orchestrating complex workflows and pipelines is essential for deriving actionable insights and driving business value.
Why choose Airflow?
Apache Airflow is a free tool that helps manage complex tasks and workflows. Think of it as a planner for your computer tasks, making sure they run in the right order without looping back on themselves. This is done through something called directed acyclic graphs (DAGs).
One of the coolest things about Airflow is that you write your workflows in code, using Python. Writing your workflows in code has lots of benefits:
You can keep track of changes over time
It’s easier to work together with others
You can test your workflows to make sure they work right
You can add your features or tools
The main benefit of using Airflow:
Flexible and extensible: Airflow can be tailored to meet your specific needs. Its extensible architecture allows for custom plugins and operators, making it adaptable to virtually any use case.
Visibility and monitoring: Airflow’s intuitive web interface provides clear visibility into your workflows, allowing you to monitor and manage tasks with ease. The interface offers detailed logs, task statuses, and execution timelines, helping you quickly identify and resolve issues.
Strong community and ecosystem: Airflow benefits from a vibrant community that continuously contributes to its improvement. This active community support ensures regular updates, a wealth of plugins, and extensive documentation. The ecosystem surrounding Airflow includes a multitude of tools and integrations, further extending its capabilities.
Use Cases
Airflow’s versatility means it can be used across a wide range of scenarios:
ETL Pipelines: Automate the extraction, transformation, and loading of data from various sources into your data warehouse.
Machine Learning Workflows: Orchestrate end-to-end machine learning pipelines, from data preprocessing to model deployment.
Data Warehousing: Manage data ingestion, transformation, and consolidation tasks in a data warehouse environment.
Real-Time Data Processing: Handle streaming data workflows with integration to real-time processing frameworks like Apache Kafka.
Custom Business Processes: Automate complex business workflows involving multiple systems and dependencies.
Getting Started
There are several ways to deploy and manage Airflow, ranging from local installations to fully managed cloud services. Let’s explore these options.

Airflow choices
1. Local Installation
For beginners or small-scale projects, installing Airflow locally on your machine is a great way to get started. This is simply as install a python library: https://airflow.apache.org/docs/apache-airflow/stable/installation/index.html#using-pypi
Or for a better approach, you can quickly set up Airflow using tools like Docker
2. Astronomer
Astronomer provides a robust platform for deploying, monitoring, and scaling Airflow. It offers a managed service that abstracts away much of the complexity involved in running Airflow at scale. With Astronomer, you can focus on building your workflows while the platform handles deployment, upgrades, and maintenance [ https://www.astronomer.io/ ].
3. Managed Cloud Services
If you prefer a fully managed solution, cloud providers like Google Cloud offer Airflow as a service. Google Cloud Composer, for example, provides a managed Airflow environment that integrates seamlessly with other Google Cloud services. This option is ideal for organizations looking for a hassle-free way to run Airflow without worrying about infrastructure management.
4. Self-hosted on Kubernetes
For those with advanced requirements and a preference for full control, deploying Airflow on a self-hosted Kubernetes cluster is a powerful option. This approach allows for maximum customization and scalability, making it suitable for large enterprises with complex workflows. Tools like Helm charts simplify the deployment process, enabling you to set up a production-grade Airflow instance with ease.
Airflow features for Data Pipelines
When it comes to orchestrating data pipelines, Airflow excels in several key areas:
Scalability
Airflow’s architecture is designed to scale horizontally, allowing you to manage thousands of tasks across numerous workflows. This scalability is crucial for handling large volumes of data and complex dependencies.
Modularity
Airflow’s modular design enables you to define tasks as independent units of work, which can be easily reused and combined in different workflows. This modularity simplifies the development and maintenance of data pipelines.
Scheduling and Dependency Management
Airflow’s powerful scheduling capabilities allow you to run workflows at specified intervals, ensuring timely data processing. Its sophisticated dependency management system ensures that tasks are executed in the correct order, based on their dependencies.
Integration with Data Ecosystems
Airflow integrates seamlessly with a wide range of data tools and services, including databases, data warehouses, cloud storage, and big data platforms. This integration capability makes it easy to build end-to-end data pipelines that leverage your existing data ecosystem.
Monitoring and Alerting
Airflow’s robust monitoring and alerting features help you track your workflows and proactively respond to issues. You can set up alerts for task failures, execution delays, and other critical events, ensuring your data pipelines run smoothly.
A typical data pipeline
The following diagram depicts a typical data pipeline from ingestion until distribution to various downstream applications. Such pipelines have the main benefit of serving as a single pane of glass for your entire orchestration of data data for a specific data product.

Airflow Astrafy typical pipeline
There are four main components in this diagram:
Ingestion: phase in which the raw data are integrated/ingested in the data warehouse (in Astrafy specific case BigQuery).
Data Quality: phase to check the integrity of the data. The goal is to avoid “garbage in, garbage out” and stop the pipeline if ingested data is corrupted.
Transformation: phase in which the data is going to be processed through SQL transformations (using dbt framework for instance) and the result of those transformations are curated datamarts ready to be used by downstream applications.
Exposure: final phase is the data activation with various downstream applications (for instance dispatching a Pub/Sub message that will trigger new ML model training, updating a data catalog tool, dispatching a message on Slack, etc.)
Conclusion
Apache Airflow is a versatile and powerful orchestrator that can elevate your data workflows to the next level. Whether you’re just starting with simple local installation or managing complex, large-scale data pipelines in the cloud, Airflow’s flexibility, scalability, and extensive integration capabilities make it the go-to choice for data orchestration.
Thank you
If you enjoyed reading this article, stay tuned as we regularly publish technical articles on Airflow and how to leverage it at best to orchestrate your data. Follow Astrafy on LinkedIn, Medium, and YouTube to be notified of the next article.
If you are starting (or eager to start) your journey with Airflow, feel free to reach out to us at sales@astrafy.io.