Blog
Optimize your Kubernetes costs in Google Cloud Platform
Reading time.
1 min
Wrtitten by
Alejandro de la Cruz López
FinOps
Google Cloud
Infra & DataOps

Introduction
If not managed properly, Kubernetes can sometimes lead to unexpected expenses. This article aims to provide practical tips for optimizing Kubernetes costs on Google Cloud Platform (GCP). We will focus on strategies to reduce the number of machines needed, which in turn reduces costs associated with CPU and memory usage. By following these tips, you can ensure that your cloud resources are used efficiently and cost-effectively.
Understanding the Cost Structure in GCP
To optimize Kubernetes costs on Google Cloud Platform (GCP), it’s crucial to understand how these costs are calculated. Google Kubernetes Engine (GKE) costs mainly come from Compute Resources, which include the Virtual Machines (VMs) that run your Kubernetes nodes.
Compute Resources
Compute costs are based on several factors:
Machine Type: Costs vary depending on the machine type. Google offers a range of machine types, from small, cost-effective instances to larger, more powerful ones.
Preemptible VMs: These short-lived instances are cheaper than regular VMs and are ideal for fault-tolerant workloads.
Sustained Use Discounts: Automatic discounts are applied to VMs that run for most of the billing month.
Committed Use Contracts: Discounts for committing to use a certain amount of resources for one or three years.
Cluster Management Fee: A management fee of $0.10 per cluster per hour.
Putting it simply, the cost of having a GKE cluster in place will be the cost of the machines that are running inside the cluster. Therefore, to optimize the cost, we need to optimize the number of machines the cluster uses.
When you create a cluster, you can define the node pool and specify the number and type of nodes. In this case, you will need to manually adapt the cluster, which is not ideal if your workloads are constantly changing. If this is your case, doing a throughout study of your workload and its consumption is key to optimizing the cost.
GKE offers autoscaling, which adjusts the number of nodes based on resource demands. The Cluster Autoscaler increases the number of nodes when resource requests exceed capacity and decreases them when there are idle resources.
GKE uses node pools, which are collections of VMs within a cluster. When using autoscaling, CPU, and memory requests are the baseline for determining the number of machines needed. Therefore, optimizing these requests is crucial. By accurately setting CPU and memory requests, you ensure that resources are used efficiently, reducing the number of machines required and lowering overall costs.

Resource Requests
Other Costs
While compute resources are the main cost drivers, storage, networking, and additional factors like load balancing and IP addresses also contribute to costs. However, these usually form a smaller proportion of the total cost, so we will not focus on them in this article.
Techniques to Optimize Kubernetes Costs in GCP
Node Pools and Preemptible VMs
Using node pools allows you to create clusters with different types of nodes tailored to specific workloads. For cost savings, consider using preemptible VMs, which are significantly cheaper than regular VMs but can be terminated by GCP with short notice. Preemptible VMs are ideal for non-critical, fault-tolerant workloads. This approach allows you to balance cost and performance by using cost-effective instances where possible.
Autoscaling
Autoscaling is a crucial feature for managing resources efficiently. GKE offers three types of autoscaling:
Horizontal Pod Autoscaler (HPA): Automatically adjusts the number of pods in a deployment based on CPU or memory utilization.
Vertical Pod Autoscaler (VPA): Automatically adjusts the resource requests and limits (CPU and memory) of pods in a deployment based on resource utilization.
Cluster Autoscaler: Increases or decreases the number of nodes in a cluster based on resource demands.
When deciding between HPA and VPA, consider the nature of your application’s needs. HPA is your go-to solution when you need to scale the number of pods in your deployment to handle fluctuating workloads. Imagine your application experiences sudden spikes in traffic or processing demands. HPA will automatically add more pods to distribute the load, ensuring your application remains responsive and performs well even under pressure.
On the other hand, VPA is ideal when you want to optimize resource utilization for your existing pods. If your pods are consistently using a high percentage of their allocated CPU or memory, but you don’t necessarily need more instances running, VPA can step in. It will intelligently increase the resource requests and limits for your pods, preventing them from being throttled and ensuring they have enough resources to perform optimally. This approach helps you avoid over-provisioning while maximizing the efficiency of your existing infrastructure.
In essence, HPA scales out by adding more pods, while VPA scales up by providing more resources to each pod. Choose the autoscaler that best aligns with your application’s specific scaling requirements.
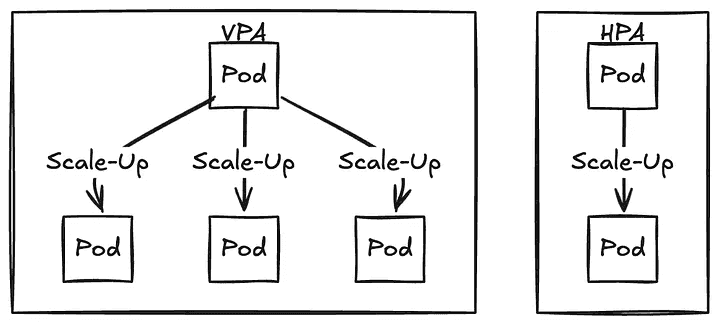
HPA vs VPA
Cluster autoscaling is a must if you don’t want to manually set the number of machines needed in your cluster. In this case, setting appropriate CPU and memory requests is a must to ensure that your cluster scales up during high demand and scales down when resources are idle, minimizing unnecessary costs.
Monitoring and Visibility with Prometheus and Grafana
Effective cost optimization requires continuous monitoring of resource usage. Prometheus and Grafana are popular open-source tools that can help:
Prometheus: Collects metrics from your Kubernetes clusters.
Grafana: Provides powerful visualization capabilities to create custom dashboards.
Using these tools, you can gain insights into resource utilization, identify underutilized resources, and make informed decisions to optimize costs.
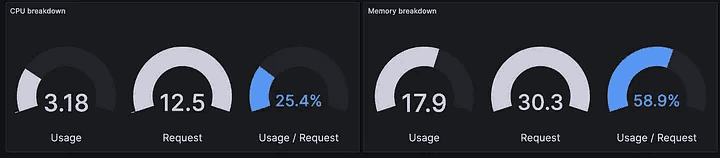
Accurate CPU and memory requests are crucial for efficient resource allocation. Overestimating requests can lead to over-provisioning, while underestimating can cause performance issues. Use monitoring solutions like Prometheus to track actual resource usage and adjust requests accordingly. This ensures that you allocate just enough resources to meet demand without overspending. Regularly reviewing and optimizing resource requests based on real-time data can significantly reduce the number of machines needed and lower overall costs.
Case Study: Real-World Example of Cost Optimization
In a recent project, we successfully reduced our Kubernetes costs on GCP by implementing several key strategies.
Moving Workloads to Preemptible VMs
We identified certain non-critical, one-off workloads that could run on preemptible VMs. By shifting these workloads, we significantly reduced costs due to the lower pricing of preemptible instances.
Optimizing Resource Requests with Grafana
Using Grafana dashboards, we monitored our cluster’s resource usage and identified over-provisioned resources. By adjusting CPU and memory requests to match actual needs, we reduced the cluster size from 7 machines to 5, eliminating unnecessary costs.
Applying Committed Use Discounts
We committed to using a specified amount of GCP resources for one year, which provided us with a 27% discount on those resources. This commitment ensured predictable usage at a lower cost.
Constant monitoring
Using Robusta KRR, we launched a regular task to run and send a report to Slack about resources that need attention due to incorrect resource requests. It will analyze the usage of the cluster and provide a report of those resources that need modification of resources.

Robusta KRR
Overall Cost Reduction
By combining these measures — using preemptible VMs, optimizing resource requests, and applying committed use discounts — we achieved a total cost reduction of 53%. This significant saving demonstrates the impact of strategic cost optimization in managing Kubernetes workloads on GCP.
Conclusion
Optimizing Kubernetes costs on Google Cloud Platform is essential for efficient resource management and budget control. By understanding the cost structure and implementing strategies like using preemptible VMs, leveraging autoscaling, and continuously monitoring resource usage with tools like Prometheus and Grafana, significant savings can be achieved. Our case study demonstrated that careful adjustment of resource requests and applying committed use discounts led to a 53% reduction in cluster costs.
These techniques ensure that your Kubernetes environment runs cost-effectively while maintaining performance and scalability. By adopting these best practices, you can maximize the value of your cloud investment and ensure sustainable cost efficiency over time.
Thank you
If you enjoyed reading this article, stay tuned as we regularly publish technical articles on FinOps, Kubernetes, and Google Cloud. Follow Astrafy on LinkedIn, Medium, and YouTube to be notified of the next article.
If you are looking for support on Modern Data Stack or Google Cloud solutions, feel free to reach out to us at sales@astrafy.io.
Written by

Alejandro de la Cruz López
Lead AI Engineer



