Blog
Leveraging Gemini LLM in BigQuery for Classification Tasks
Reading time.
1 min
Wrtitten by
Greta Lerer
Artificial Intelligence

In this article, we’re going to explore the implementation of Gemini — Google’s state-of-the-art LLM family to help with transformation tasks
If you’re familiar with the tech world, you know that OpenAI’s ChatGPT reached 1 million users in just 5 days. In comparison, Netflix took 3.5 years, and Twitter took 2 years. These numbers highlight how rapidly LLMs are becoming ingrained in our lives. For developers, this means two things:
Learning to create your own LLMs
Leveraging existing ones to your advantage.
In this article, we will explore the second option in combination with BigQuery to enhance the transformation process of Google Analytics data.
Objective
In the fast-paced world of e-commerce, understanding website traffic is crucial. It’s the lifeblood of marketing strategies, driving decisions on content creation, user engagement, and overall business growth. Accurate traffic analysis enables companies to optimize their online presence, tailor their marketing efforts, and ultimately, increase conversions and customer satisfaction.
Overall, as data analysts in the marketing scope, we want to understand the traction that each solution page generates, to investigate:
Which pages are attracting the most interest from potential clients.
How users navigate through our website and interact with different pages.
Where to focus our marketing efforts based on user engagement and traffic patterns.
Potential areas for improving content and user experience on less-visited pages.
Overall trends in user behavior that can inform our strategic planning and decision-making.
For example, in the context of an e-commerce website, understanding how users move through product pages can reveal which products are most appealing and where marketing efforts should be concentrated. Similarly, for our service pages at Astrafy, we aim to uncover valuable insights to enhance user engagement and optimize our offerings.
For our particular case, at Astrafy, we need metrics on how the traffic to our website is distributed among our services. Hereafter are all the services we offer (and a little bit of self-promo Astrafy):

The challenge is that while we can extract URL locations where events happened from Google Analytics 4, transforming this data into an actionable categorization system is complex. At Astrafy, we’ve already defined a generalizable GA4 model, which we have been using internally and with our clients. Our goal now is to enhance that model using AI capabilities.
Note: Initially, we tried to categorize using REGEX to extract the service’s names from URLs, for example: https://astrafy.io/services/advanced-analytics to get “Services — Advanced Analytics.” However, there were too many exceptions to the common URL pattern that we had to account for. Consider these examples:
https://astrafy.io/es/services/advanced-analytics (Spanish version with /es/)
https://astrafy.io/services/advanced-analytics?ref=homepage (URLs with query parameters)
https://astrafy.io/en/services/advanced-analytics#section2 (URLs with hash fragments).
Those variations made it difficult to create a REGEX pattern that could accurately and consistently extract service names. For instance, simple functions like split() by “/” and taking the last value would fail with URLs like https://astrafy.io/en/services/advanced-analytics#section2, where the result would incorrectly be “advanced-analytics#section2.”
This led us to realize that we needed to leverage machine learning for a more robust solution. We decided to implement this solution exclusively using BigQuery, leveraging its machine learning capabilities, which are both new and easy to use. For more information on how to create ML models in BigQuery, you can refer to the BigQuery SQL ML Documentation.
Why Choose an LLM for Data Categorization:
At first sight, we considered using a traditional ML model. However, this approach has significant limitations:
Dependence on Historical Data: Traditional models require extensive historical data for training. This data dependency can limit the model’s ability to generalize and adapt to new, unseen data.
Struggles with Unseen Data: Once trained, the model may struggle to adapt to new and unseen data, as it has already encountered all possible links within the training set. This poses a challenge as our web page continues to grow and new categories emerge.
Inefficient Training Time: Training traditional models is time-consuming. In our case, it takes almost 5 minutes per model, which is inefficient for iterative development and real-time updates.
In contrast, implementing a Large Language Model (LLM) offers several advantages:
Minimal Data Dependency: LLMs are pre-trained on vast datasets, reducing the need for extensive historical data and enabling the model to generalize better across various scenarios.
Adaptability: LLMs are designed to handle new and unseen data more effectively, adapting to changes and growth in the web page seamlessly.
Efficiency: The rapid activation time of an LLM, just 15 seconds in our case, significantly reduces the wait time for model updates and data processing.
Scalability and Future-Proofing: By using an LLM, our data categorization system becomes more robust against future changes and expansions, ensuring it remains efficient and effective as the web page evolves.
Overall, while traditional models may work well for stable websites with confident existing categorization, an LLM provides the necessary flexibility and efficiency for dynamic and evolving data environments.
Using Gemini
It was a no-brainer that this was the perfect use case for a pre-trained LLM, whose key advantage, in this context, is that you don’t need a training and testing dataset (as long as you decide not to fine-tune).
It’s crucial to follow good prompt engineering practices, especially with Gemini. Google provides documentation on how to frame queries based on the model’s training. Briefly, these are the guidelines to follow:
Be Clear and Specific: Ensure prompts are precise and unambiguous.
Use Examples: Provide input and output examples to guide the model.
Iterate and Refine: Continuously test and improve your prompts.
Leverage Context: Include relevant background information.
Monitor and Adjust: Regularly check performance and tweak prompts as needed.
Regarding the model we chose, upon playing around on Google AI Studio, we opted for Gemini 1.5 pro, whose results even amazed us, strong rooters for ChatGPT. At Astrafy, we see prompt engineering and model selection as a hand-in-hand process, as all models need their prompt adaptation.
The best part of the process is how easy and intuitive BigQuery makes this whole process. The prompt used was the following:
I have a list of URLs. Please analyse the structure and content of each URL and assign it to the most appropriate category from the following:
- Homepage: Main landing page for the page. URL domain.
Services: Pages dedicated to showcasing the specific services offered by the company. If you choose this one, please also include a subcategory.
- Methodology: Pages explaining the company’s approach, processes, or frameworks for delivering their services.
- The Hub: Pages related to all technical documentation articles and content generated by the company.
- Academy: Pages related to educational resources or programs offered by the company.
- About: Pages providing information about the company, its mission, history, or team.
- Careers: Pages related to job openings or information about working at the company.
Please ONLY return the categorization, no explanations.
Note: We know it’s a long prompt, but by experimenting and by following the best practices advice, we found that even LLMs need some context and guidance. In addition, the long prompt did not significantly affect runtime.
Code to classify:
Generated output:
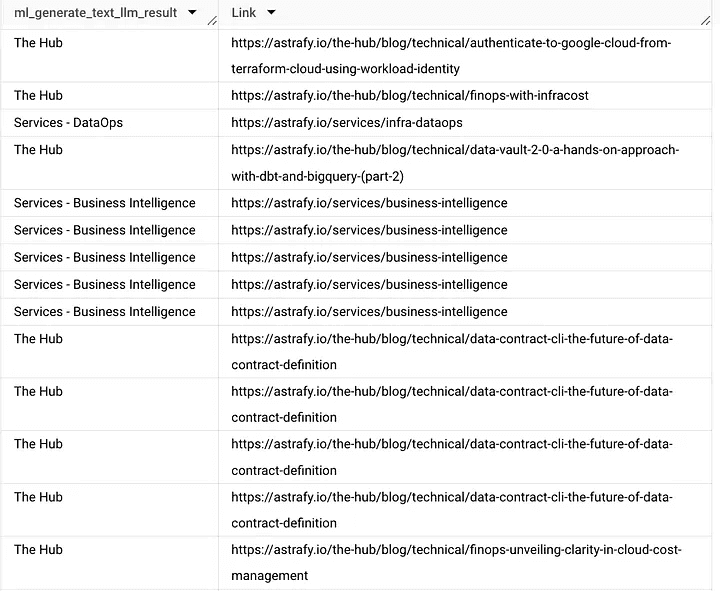
We are fairly surprised and confident with this output.
Future expansion
The obvious way to go from here is ✨fine-tuning✨
Reasons why to fine-tune:
Ensures no undesired categories are randomly generated, i.e., gives the model some more “guidance”.
Makes it context-specific.
Reasons why not to fine-tune:
Removes generalizability.
Relies on a training dataset.
For BigQuery LLMs (which sit on Vertex AI), finetuning requires you to EXCLUSIVELY use text-bison, a model I don’t particularly sympathize with. In some way, it could be thought of as a tradeoff between model performance and fine-tuning.
Regarding further possible implementations, one possible use case is to categorize web pages rather than from their page_location URL, from their content. Categorizing web pages based on their content rather than their URLs is crucial, especially for older websites with outdated or poorly planned URL structures. These legacy URLs often do not accurately reflect the page’s content, leading to inefficiencies in content management and user navigation. By analyzing the actual content of the pages, a more accurate and meaningful categorization can be achieved, improving both search engine optimization and user experience, among other things.
Large Language Models (LLMs) facilitate this process by automating content analysis and classification. LLMs can efficiently process large volumes of text, identifying themes and patterns that enable precise categorization. This not only saves time but also ensures accuracy, making content management more effective and scalable. Utilizing LLMs for content-based categorization helps address the limitations of URL-based systems, ensuring that web pages are organized in a way that truly reflects their content.
Conclusion
In this article, we explored how leveraging state-of-the-art language models like Gemini can enhance the data engineering process. We used Gemini for flexible and robust classification while addressing the complexities inherent in our data structure.
By sharing this implementation, we hope to inspire other data engineers and developers to explore the capabilities of LLMs and machine learning models in their own projects. The rapid integration of these technologies into our workflows underscores their growing importance and the exciting possibilities they offer for the future of data engineering.
Thank you
If you enjoyed reading this article, stay tuned as we regularly publish technical articles on Google Cloud and how to leverage it at best without compromising on security. Follow Astrafy on LinkedIn to be notified of the next article ;).
If you are looking for support on Modern Data Stack or Google Cloud solutions, feel free to reach out to us at sales@astrafy.io.
Written by

Greta Lerer
Data Analyst & BI Engineer



