Blog
Data Stack Infra & Security Foundations on Google Cloud
Reading time.
3 min
Wrtitten by
Charles Verleyen
Infra & DataOps
Security
Data Strategy

Introduction
This article will deep dive into the Infrastructure & security foundations required for your data stack ecosystem to work properly. As depicted in the illustration below, everyone dreams of the sexy BI dashboards, ML & Gen AI applications but everyone seems to disregard the fact that strong infra & security foundations are required for those downstream activities to perform well.
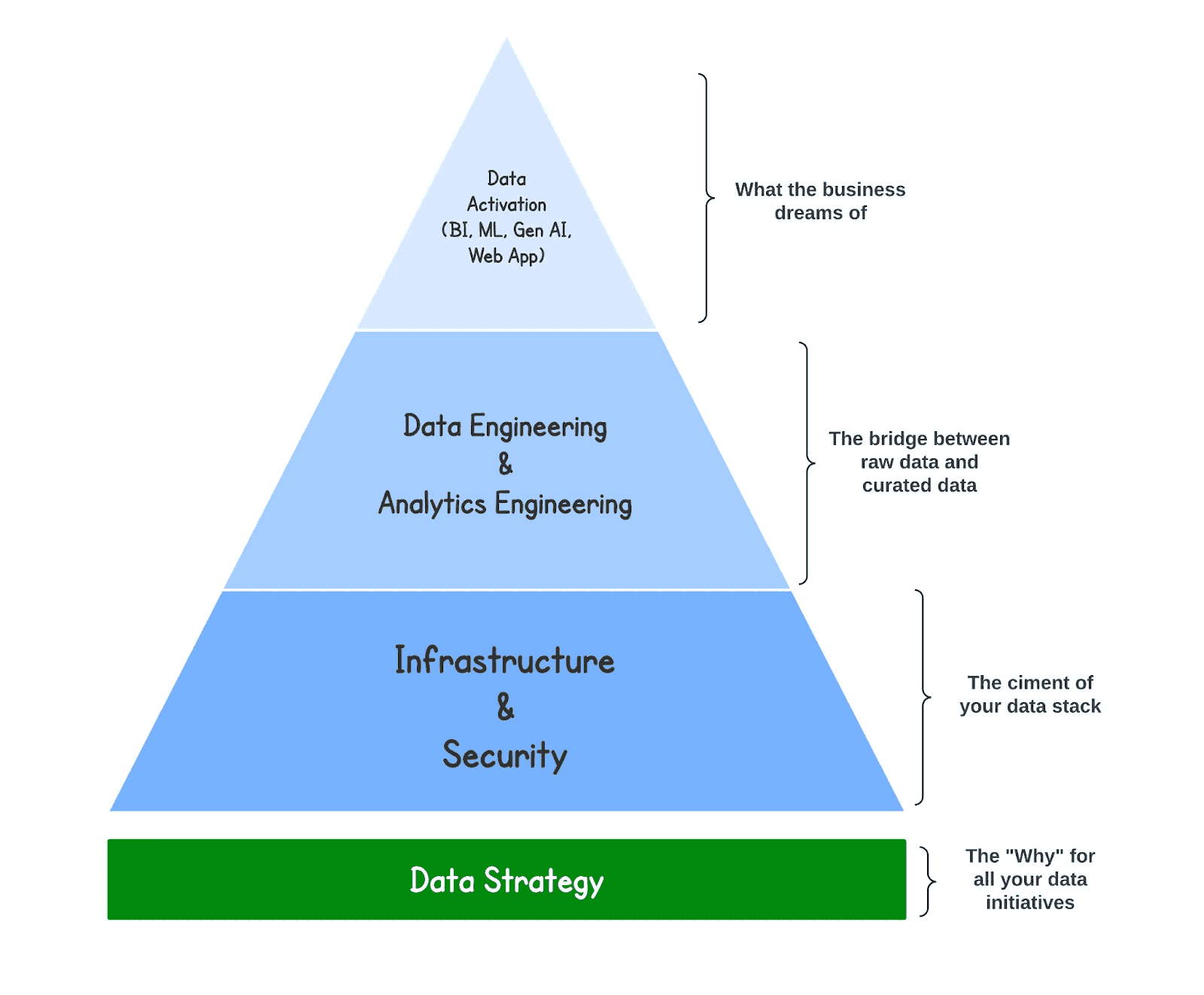
This article won’t be technology-agnostic as it will focus on Infrastructure & Security foundations for Google Cloud but the concepts covered in this article are global and can be applied to any other Cloud providers.
You can use this article as a conceptual cookbook, or even better, reach out to us to use an accelerator we have built around those best-practice infra and security foundations. There is no need to reinvent the wheel, and we can support you in jumping-starting a strong foundation in a matter of a few days.
Data is a product within a large ecosystem
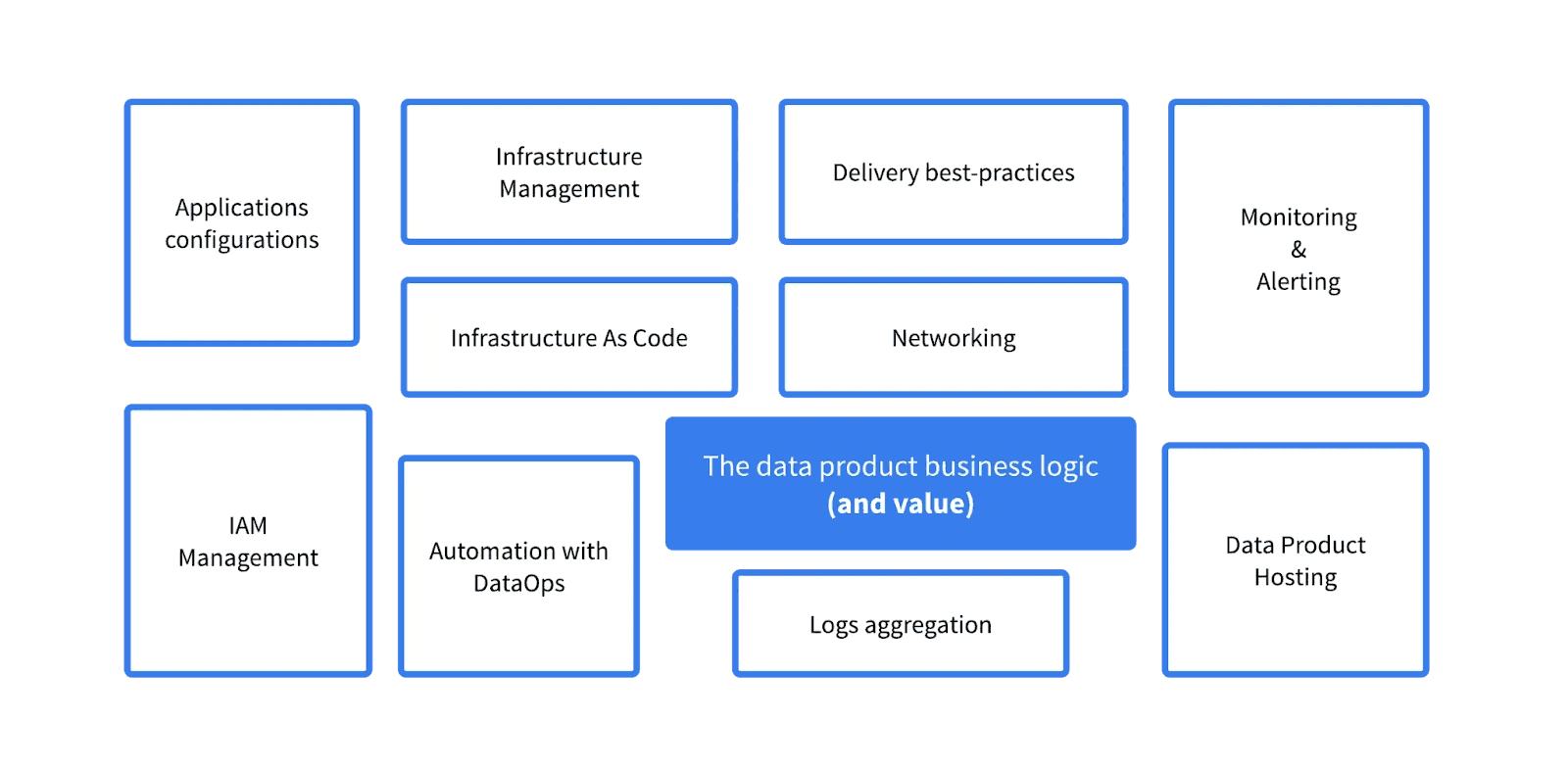
Data in production requires many components to move seamlessly from ingestion to distribution. As the illustration below shows, the data and its business logic represent only one part of a much bigger ecosystem.
Most of the time, data teams focus on the data product and other teams handle the other components in a kind of siloed approach. This then leads to inefficiencies with tools that cannot integrate well together, lack of automation in key activities, security loopholes, etc.
Once data teams understand that data must be treated in a more holistic approach as a product/asset, transversal teams are created, and those act with a common purpose of adding value to the business. The Data Mesh architecture goes in that sense by having data product teams consisting of team members producing the data (software engineers) until the consumers of this data. All those independent data product teams are then served in terms of infrastructure and governance/security by two federated teams (one for the infrastructure and one for the governance).
The infra team provides the necessary infrastructure to each data product team so that they can run their data product seamlessly with all the necessary automation and monitoring. This lets the data product team focus on transforming the data without worrying about the infra part.
The governance/security team sets the policies for each data product team to follow. They define the roles that can be given, regions where data can be stored, how data can be shared, etc. Most of those policies are automatically enforced and provide global security standards for the company.
The illustration below (credit to datamesh-architecture.com) summarizes well how data mesh teams should be structured:
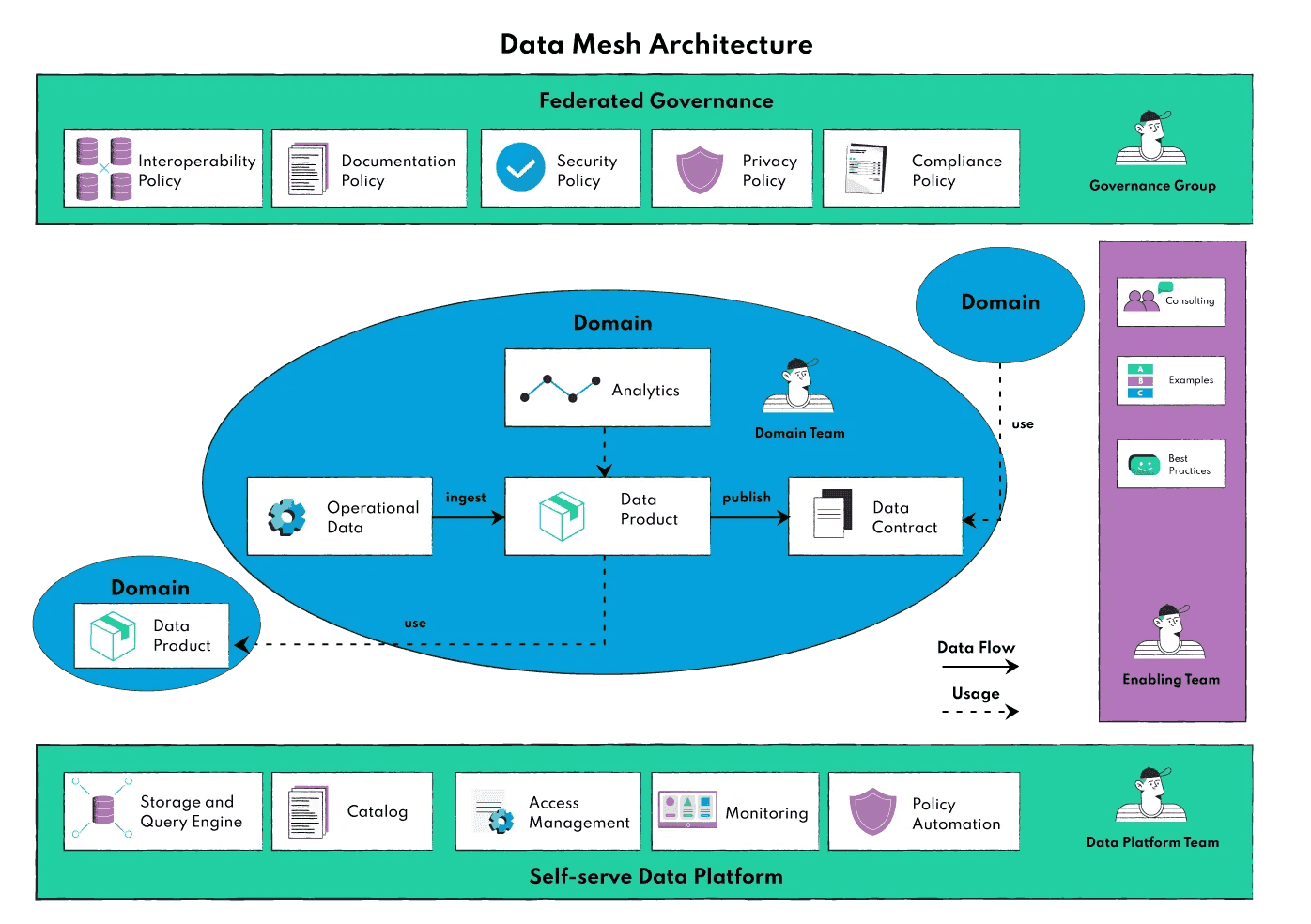
The rest of this article will focus on the two green rectangles and how to best implement those within Google Cloud. The “Self-serve Data Platform” is associated with the Infrastructure section and the “Federated Governance” with the Security section.
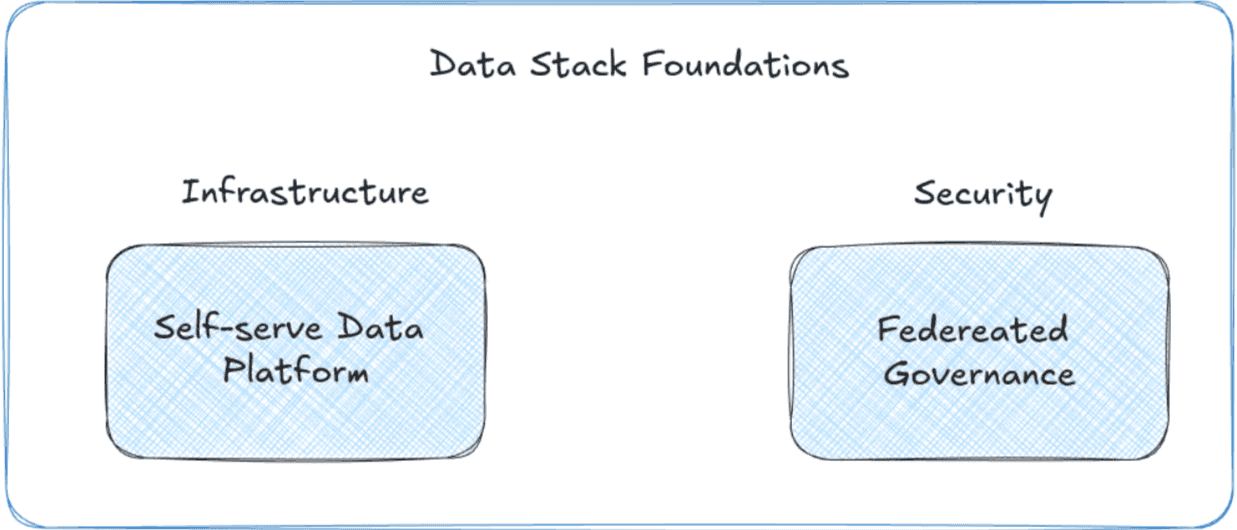
Data products in the context of this article are to be understood as technical data assets and not business analytical products (check this article from Dylan Anderson for more details on this distinction).
Infrastructure
Data Infrastructure is about the different cloud assets empowering your data to flow smoothly and seamlessly from your source systems to your curated datamarts. This infrastructure needs to have the following characteristics to perform well:
Automation: Deploying the data infrastructure needs to be fully automated. If it’s not the case, the “Self Serve” aspect will not work and you will end up with fragmented pieces of infrastructure deployed without control. To automate your infrastructure deployment and keep visibility on what is deployed, the use of an Infrastructure as Code tool is mandatory. Terraform for instance does a great job and can deploy resources on all the Cloud providers and hundreds of other applications.
Scalable: Choose resources that scale by default. One of the benefits of being on the Cloud is that you can leverage unlimited computing power but you need to make sure you deploy cloud resources that will scale automatically without much tweaking and configurations.
Modular: The “one tool that does it all” is an urban myth and aggressive marketing tactic some tools use. Ingesting data, transforming data, orchestrating data, etc., require specific tools that excel in their respective fields. Having modularity in your data infrastructure stack also gives you the benefit of less vendor lock-in.
Secured: The Security section below will tackle this characteristic in detail. In summary, you need an infrastructure that has security embedded at all levels and will proactively block and notify users when security concerns arise.
The following subsections will detail how to deploy a state-of-the-art data infrastructure on Google Cloud. Google Cloud is one of the best cloud providers in terms of data resources, and deploying an efficient “Self-Serve” data infrastructure on it is easy.
Organization, Folders and Projects
Google Cloud has three levels of hierarchy:
Organization: is the root node and represents your company. It is associated with the domain of your company and your Cloud Identity is linked to that organization domain. The organization is the root node and is the main ancestor of all the folders and projects.
Folders: Folders in Google Cloud allow you to create a structured and organized hierarchy of your cloud resources. They function similarly to folders on your computer, helping to organize projects in a way that makes management and security more streamlined. The key purpose of folders is to group similar projects or departments, allowing for easier access control and policy inheritance.
Projects: Projects are the lowest level in Google Cloud’s resource hierarchy and serve as containers for all of your resources, such as compute instances, storage, and networks. Each project is associated with billing, access control, and API configuration, making it the operational unit within the Google Cloud ecosystem.
Best Practices for Folders and Projects
Granularity is Key: It’s better to create multiple smaller projects and folders than to lump everything into one. This will provide better security and more precise access control.
Leverage Hierarchical Policies: Policies set at higher levels (like organization or folder) automatically apply to all child resources. This reduces the risk of misconfigurations and helps ensure consistent security and governance across your projects.
Separate Environments: Use different projects for production, development, and testing environments. This will ensure that your production resources are isolated and secure.
Delegate Administrative Roles: Use folders to delegate project control to different teams, allowing them to manage their own resources without impacting others.
We will now detail a few infrastructure design patterns. The following architecture depicts what you should first deploy:
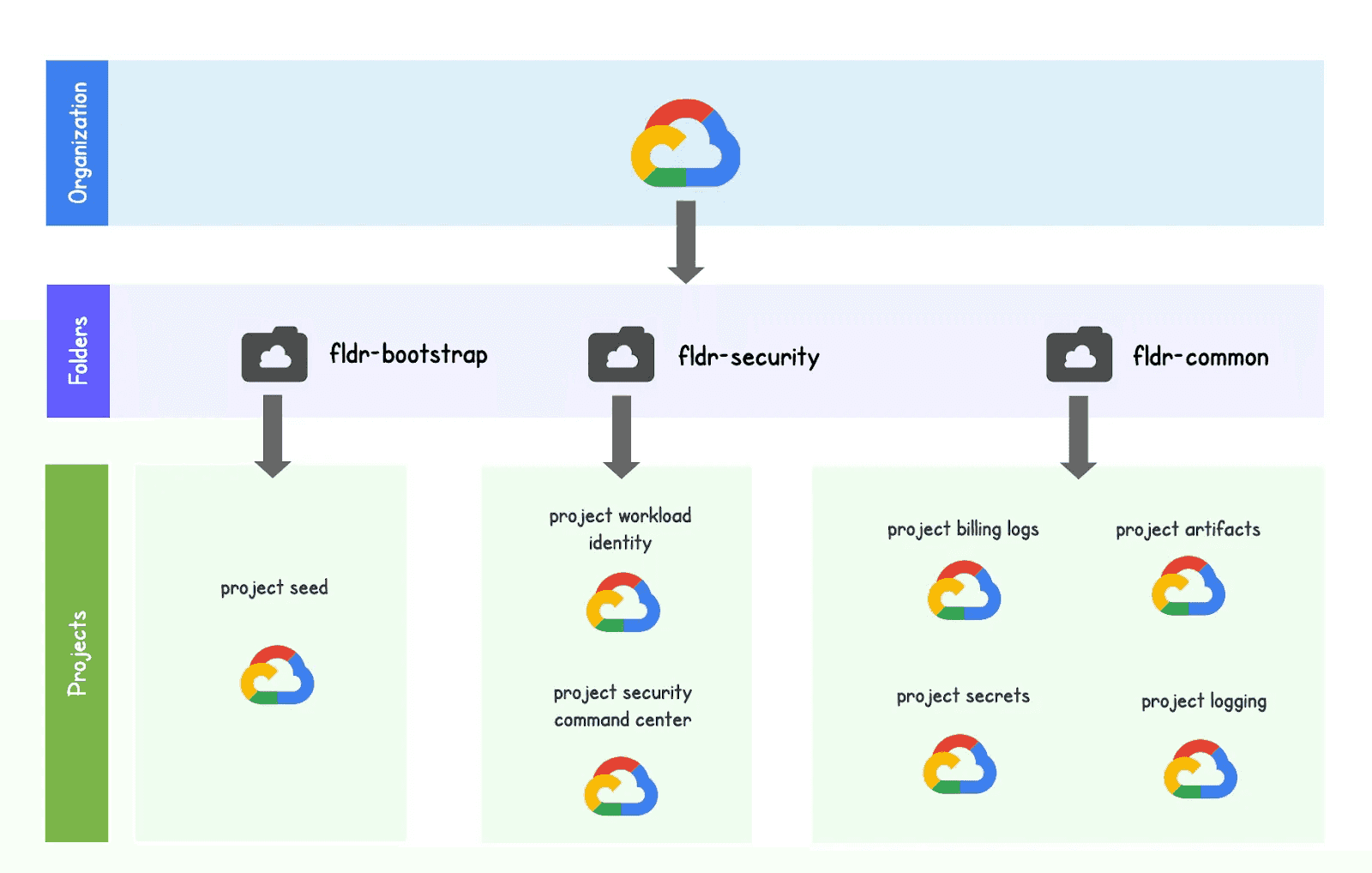
fldr-bootstrap: you need a project to create the first service account that you can then assign to terraform workspaces to deploy other resources. The only purpose of this genesis folder and project is to initialize a few master service accounts that will be used by Terraform to deploy Google Cloud resources.
fldr-security: this folder contains two projects. One for that will host all the resources related to workload identity and one that will centralize all the security findings from your organization through the security command center. More on those two projects in the security section.
fldr-common: this folder contains four projects. One to centralize the billing export, one that contains all the log sinks of the organization, one for the organization’s secrets and finally one for the different artifacts (docker images, etc.).
This split allows for better visibility, a clear separation of concerns, and much easier control of access.
A second design pattern relates to sandbox projects for each of your developers. As mentioned, you want 100% of your resources deployed in Terraform but at the same time, you want to give a playground to your developers to test new products quickly. This is achieved by provisioning one sandbox project per developer and assigning them owner roles. To avoid cost outbursts, you can set up quotas and automate the deactivation of billing once a specific monthly threshold budget is reached. The following architecture depicts those sandbox projects.
![Diagram illustrating a Google Cloud sandbox environment, showing an organized hierarchy with a sandbox folder containing multiple personalized sandbox projects (named using placeholders like sbx-[FIRST NAME]-[LAST NAME]), providing users with isolated spaces for experimentation and development.](https://framerusercontent.com/images/b41cnft7J80AkWrXu2V9dAponig.png)
Data Products infrastructure
Once you have the basic foundations in place, it’s time to start deploying the data infrastructure. This deployment has two parts.
The infrastructure you deploy will evolve over time, and even more so if you have a data mesh organization structure where each team has the flexibility to deploy some infrastructure on a “self-serve” basis. In concrete terms, each data product team will need to be able to deploy the following infrastructure:
BigQuery Datasets to store tables
DAGs to orchestrate the transformation of data
Git repositories for code to transform and orchestrate data
It seems very few artifacts are needed and that’s the whole goal of keeping it very simple for data product teams to be autonomous. The complexity relies on the automation and the process you have behind all this infrastructure to act as a whole. This complexity is abstracted away for an end-user that in the end, only has to perform the following actions to have the necessary infrastructure up and running for a new data product:

This will have bootstrapped the necessary resources for data/analytics engineers to start working with their data product. BigQuery datasets will have been created with accurate IAM bindings, Git repositories will have the CI pipelines in place with Git variables and secrets defined per environment, Git repository for transformation will contain the skeleton with all the necessary structure to start writing dbt models and materialize those, an Airflow DAG will already be in the UI waiting to be activated, etc.
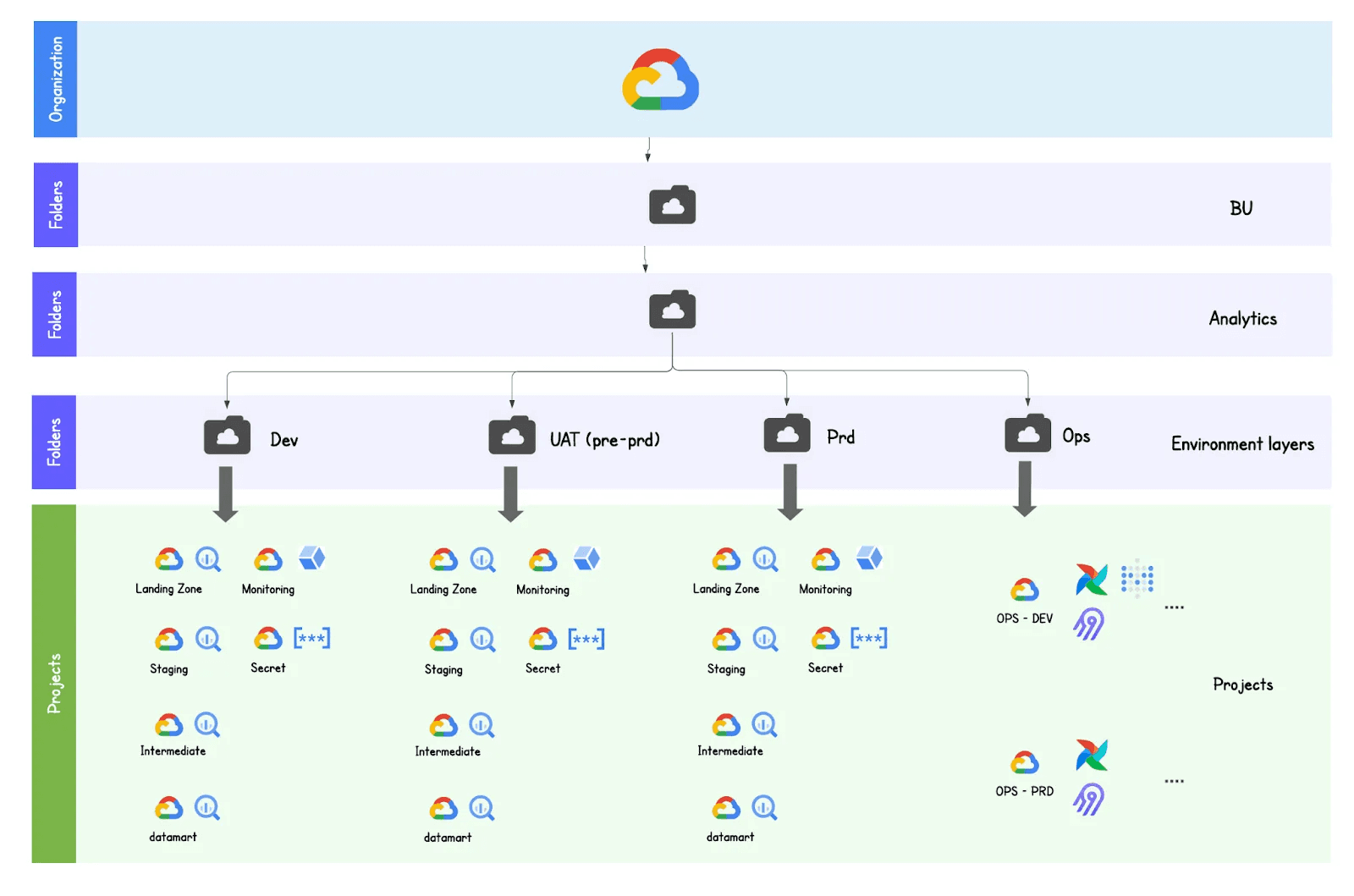
Regarding the data infrastructure, a good design (as mentioned above) is to have one Google Cloud project per data layer (you can interchange Staging, Intermediate and data mart with the Medalion equivalent of Bronze, Silver and Gold) and then datasets within those projects representing data products. The following illustration depicts this:

This architecture makes it easy and convenient to navigate through your different data products in BigQuery, allows for simple interoperability and simplifies security.
A big part of the infrastructure component resides in the data applications deployed in a scalable and well-integrated way. Quite some engineering and tweaking is required to deploy top-notch applications via OSS on a Kubernetes cluster, and we have written extensively about it in this article. In a nutshell, this data apps stack that is entirely running on GKE is composed of:
Airbyte for ingesting data
Airflow to orchestrate data pipelines from ingestion to distribution
Datahub for data cataloging
There are hundreds of tools for each of those functions and the use and integration of the tools matter much more in the end than the tools themselves. Those mentioned tools have a large community, are stable and lend themselves pretty well to deployments on Kubernetes. And maybe most importantly, those tools integrate very well with each other and with the Google Cloud stack. Once deployed and configured, those tools work automatically for you; Airflow triggers Airbyte ingeste, then triggers transformations, then dispatches metadata to Datahub and the BI tool directly consumes new data from datamarts. Everything flows seamlessly.
Networking
Networking is a critical and often underestimated foundation of your infrastructure, as weak network design frequently serves as the entry point for most cyber-attacks and performance issues. A well-architected network design on Google Cloud not only secures your data and applications but also ensures optimal performance and scalability. Some key components of Robust Network Design:
Shared VPC Architecture
Utilize Google Cloud’s Shared VPC to centralize network administration. A Shared VPC allows the central management of VPC networks from host projects, enabling resources from multiple service projects to securely communicate within a unified private network.
Segregate development and production environments into distinct host projects to ensure isolation and security.
2. Subnet Management
Structure your subnets carefully by environment (development, staging, production), function (analytics, operations), and region to facilitate efficient traffic management and enforce granular firewall rules.
Adopt CIDR block best practices, allocating IP ranges in a structured way to avoid overlapping, which could cause conflicts or network performance degradation.
3. Firewall Rules and Security
Enforce strict firewall rules with default-deny policies. Only explicitly defined traffic should be permitted.
4. Private Access and NAT
Ensure that workloads without public IP addresses can access Google APIs and services securely via Private Google Access.
Use Cloud NAT to provide internet access to private instances without exposing them directly to the internet, significantly reducing the attack surface.
The following architecture depicts this networking design:

Networking is mainly needed for the GKE cluster that hosts the different data applications but other subnets might be created based on your needs (Vertex AI workbench requires networking for instance, etc.).
Downstream applications
This is the visible part of the iceberg for the business, where data is finally activated to generate tangible value. The infrastructure supporting these applications may reside within the applications themselves — for example, within BI tools — or can leverage Google Cloud’s powerful managed services.
On Google Cloud, Vertex AI serves as a robust, managed platform facilitating Machine Learning and Generative AI workloads. It allows data scientists and developers to rapidly deploy, monitor, and scale AI models in production without worrying about underlying infrastructure complexities.
Additionally, organizations can leverage Google Cloud Functions or Cloud Run to develop and host APIs for real-time data interaction, thereby integrating data products directly into operational workflows. These services allow applications to consume analytics outputs and model predictions seamlessly, enhancing decision-making processes.
For visualization and reporting, tools such as Looker, Data Studio, Metabase, or Superset can integrate directly with your Google Cloud data infrastructure, providing intuitive, insightful analytics to stakeholders across the business.
Moreover, ensuring that downstream applications have dedicated Google Cloud projects facilitates clear resource management, tailored access controls, and efficient cost tracking. By adopting a structured approach — separating concerns clearly between data infrastructure and the downstream applications — you maintain scalability, enhance security, and accelerate the value realization from your data stack.
The following illustration depicts the different families of downstream applications and regardless if those are products hosted on dedicated Google Cloud projects or data applications, they all fetch data from BigQuery tables located in the datamart projects.

Infrastructure as Code
“Infrastructure as Code” (IaC) is the elephant in the room we have not mentioned since the beginning of this article. It is indispensable that your infrastructure is defined and managed through code, using tools such as Terraform. Codifying your infrastructure ensures consistency, repeatability, and version control, significantly enhancing your team’s productivity and reducing manual configuration errors.
We recommend having a granular approach to Terraform with many repositories corresponding to specific families of resources to be deployed. Each repository is linked to one or many Terraform Cloud workspaces (when deploying on multiple environments) that listen to changes in specific directories. The following diagram is not exhaustive but illustrates this principle of going granular in terms of infrastructure repositories. It has only benefits in terms of structure, security and velocity.
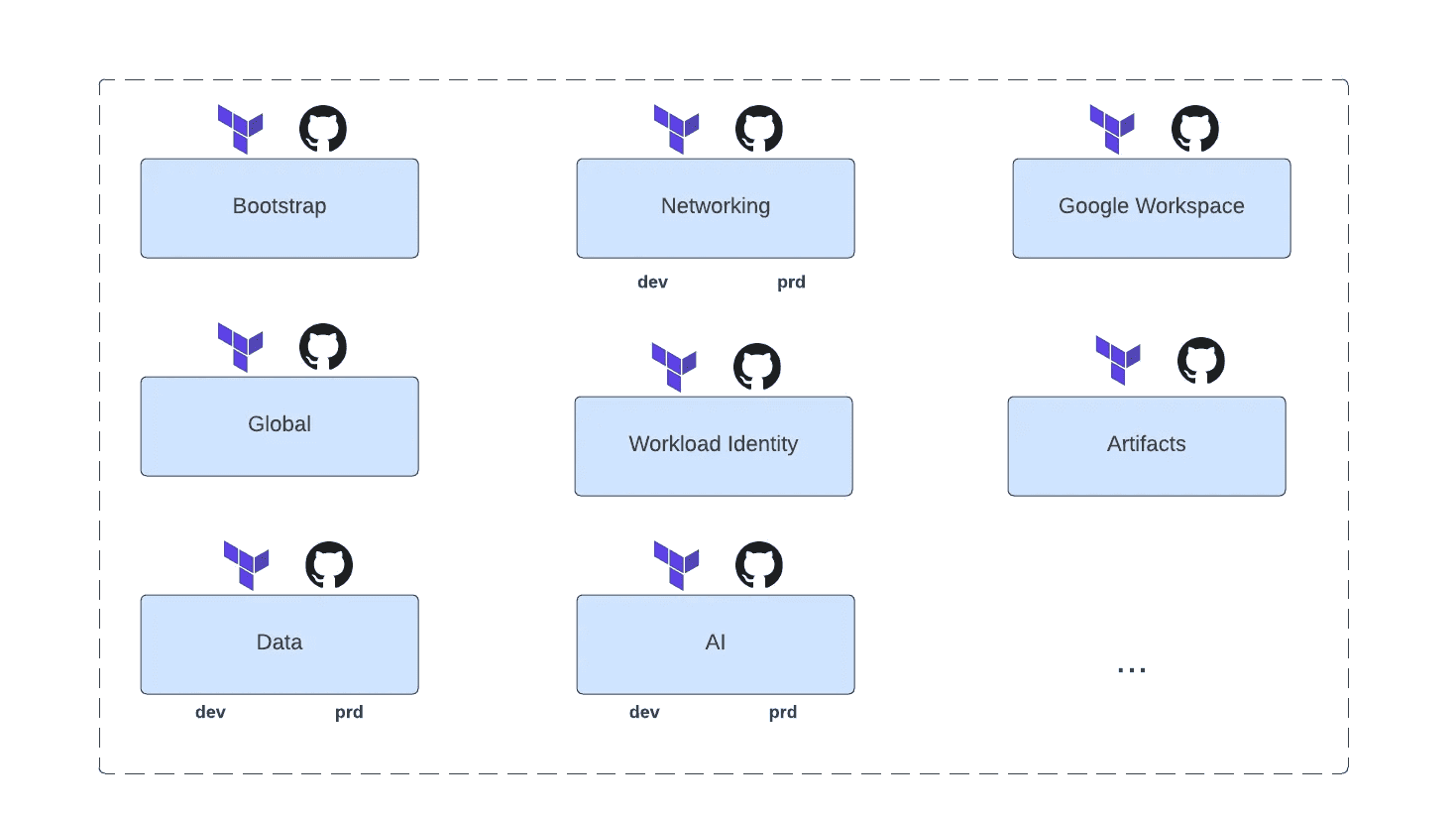
Asset Inventory
Cloud Asset Inventory gives you visibility on all the resources deployed within your Google Cloud organization.
Not directly related to asset inventory but equally important is adopting a robust labeling strategy. Most Google Cloud resources support labels, which can be managed via Terraform parameters. In data transformation workflows using dbt, leverage the query_comment macro and set job-label to true, embedding vital metadata as labels on your BigQuery jobs. This practice significantly enhances granular monitoring and auditing capabilities, offering valuable insights into resource utilization and analytics job performance.
Security
Google core principles include defense in depth, at scale, and by default. In Google Cloud, data and systems are protected through multiple layered defences using policies and controls that are configured across IAM, encryption, networking, detection, logging, and monitoring.
Google Cloud is definitely the best Cloud in terms of security but most cloud security breaches are the direct result of misconfiguration (listed as number 3 in the Cloud Security Alliance’s Pandemic 11 Report) and this trend is expected to increase. Therefore it’s of major importance to configure with the utmost care the security aspect within your scope of responsibility.
Holistic approach
Security is a first-class citizen that must be part of discussion and design from day 0. Security must never be compromised for anything; not speed, not agility, nothing.
Governance around your global infrastructure is of major importance as data leakage and security breaches are becoming increasingly common. Security responsibility lies, therefore, mainly in securing access within your own organization with security postures such as:
Networking centralized in one project: networking is most of the time where outside attacks can occur. If everything is private, risks of an outside attack are close to 0. For this reason, we apply Google recommendations of deactivating networking on every project and centralizing all networking via shared VPC on one dev and one prod project. This shared VPC then shares subnets with projects that need networking.
Least-privileged access philosophy applied for all IAM bindings. This translates into granular roles given to identities to be able the tasks they need to do and nothing more. Only Terraform Cloud Service Accounts have elevated roles as they are responsible to deploy the main infrastructure but those Service Accounts are very secured with no one being able to impersonate those and they can only deploy resources via Terraform workspaces.
Segregation of duty is fundamental to ensuring that one identity or one Terraform workspace can do everything. This accelerator is very granular in the number of infrastructure repositories as well as in the family of identities (large number of groups, service accounts, etc.).
And this list is far from being exhaustive but the important point to keep in mind is that every deployment goes first through a security design process to then move with an implementation that includes as many security features as possible.
Security can sometimes be annoying, but good governance is a “must-have” in today’s world to avoid making the headlights in the newspaper.
Good design and implementation of security does not slow down innovation. The design in place sets utmost security rules while keeping innovation and agility high through sandbox projects, fast iteration on setting new IAM bindings if necessary, etc.
Data Products governance
Data Mesh promotes a federated governance. Similarly to the infrastructure part, design, guidelines, implementation, and controls are managed by a federated authority. This ensures that everyone abides by the same global policies and that despite the decentralization of analytics, governance rules remain the responsibility of one department that has a holistic view on global security of the company. The following schema from https://www.datamesh-governance.com/ depicts perfectly how this federated governance applies for data products.

Global policies are defined and enforced by a global governance team, and those policies are then automated via code, tests, and monitoring. Federated governance doesn’t translate into rigid security, as data product teams can assign IAM bindings and implement security measures. It’s just that those security deployments are strictly governed through code (assigning someone the owner role would be rejected by Terraform tests) and then monitored by the security team.
IAM bindings
Always think “least privileged access” and “segregation of duty” when dealing with IAM bindings. You should for instance:
Create one group per data product per environment
Create one service account per data product per environment
Create one service account per engine (Cloud Run, Cloud Functions, etc.)
…
And for each of those identities, you give it only the minimum set of roles required. Being that granular reduces the blast radius if an identity is corrupted. The following diagram depicts roles associated with a service account at a data product level:

As you can see, the service account only has
Access the datasets of the concerned data product
Job user role on one Google Cloud project in order to centralize all queries in on project
And regarding IAM bindings for users, you must always grant those access at the group level and never at the user level. This best practice makes it easy to onboard and offboard users; you just add or remove them from a specific group, and their roles are adapted accordingly. Ideally, you would assign roles similar roles to groups to service accounts except for production, where you would remove the permissions to temper the tables (only roles to view and query).
In addition to the least-privilege and segregation-of-duty principles outlined above, you can further harden and simplify your IAM posture by leveraging:
IAM Conditions: Attach context-aware, attribute-based conditions to your IAM bindings so that roles are only granted when specific criteria are met (e.g. time of day, request origin, or resource tags). This lets you enforce policies like “allow BigQuery read access only from our corporate IP range” or “grant admin rights only during on-call windows,” reducing risk without proliferating bespoke roles.
Privileged Access Management (PAM) for Temporary Access: Employ a PAM solution to grant just-in-time elevation. Rather than permanently assigning high-risk roles, users or service accounts request temporary permissions that automatically expire. This dramatically shrinks the window in which compromised credentials can harm.
Principal Access Boundary (PAB) for Scoping Access
Define a boundary policy on the identities you control so that you can prevnet them for instance to access resources outside of your organization. With PAB policies, you can define the resources that a principal is eligible to access. It adds a security layer on top of the normal IAM bindings; a user might have the roles to access a resource but if a PAB policy denies access to that resource, the user won’t have access.

Workload Identity
Workload identity allows applications outside of Google CLodu to leverage permissions to act on your Google Cloud organization without the need for a service account key. It’s a keyless mechanism with short-lived tokens issued on demand, automatically scoped by the Workload Identity configuration.
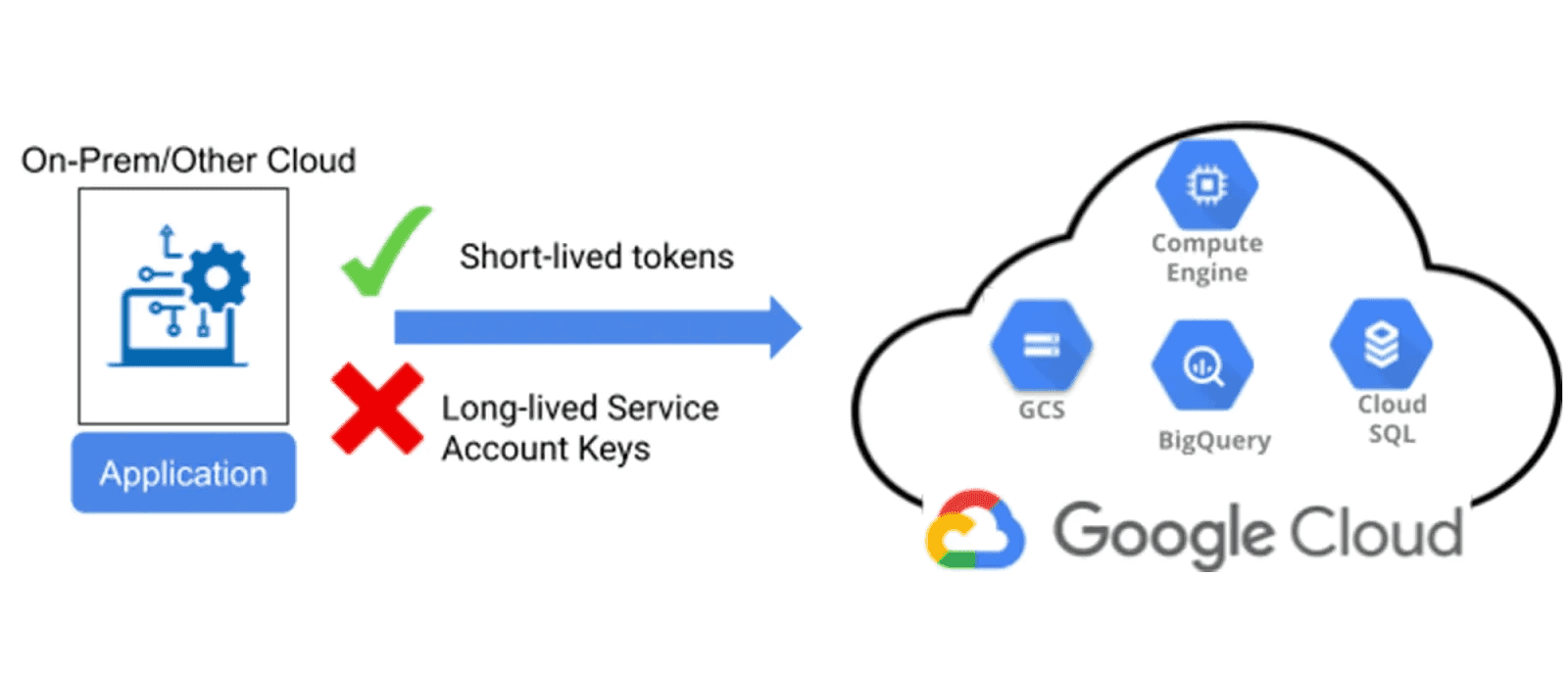
As soon as you need an external application to act on your Google CLodu organizaiton, you need first look at the possibility of setting up Workload Identity instead of service account keys that represent a higher security risk due to potential leakage.
In case of setting up a data infrastructure, you will do this setup in two direct applications: Terraform Cloud and Github (or any other git platform). Those two applications natively support the use of workload identity, and you will then be able to associate one service account with a specific Terraform Cloud workspace or Github repository.
Oganization policies
The Organization Policy product gives you centralised and programmatic policy control over your organisation’s Google Cloud resources. It allows you to configure constraints across your entire resource hierarchy. Benefits are as follows:
Centralize control to configure restrictions on how your organisation’s resources can be used.
Define and establish guardrails for your development teams to stay within compliance boundaries.
Help project owners and their teams move quickly without worry of breaking compliance.
What is the differences from Identity and Access Management (IAM) ? IAM on who, and lets the administrator authorize who can take action on specific resources based on permissions. Organization Policy focuses on what, and lets the administrator set restrictions on specific resources to determine how they can be configured.
Some Interesting organization policies to enforce:
Resource location: you can enforce specific locations (regions and zones) for your resources. Anyone trying to deploy a resource in a location not listed in the org policy will get an error.
Service account key creation: you can disable the possibility for anyone to create service account keys.
Domain restricted sharing: you can enforce that only specific domains can be allowed for IAM bindings. This ensures that all identities that have access to your organization are actually managed by your organization as well.
There exist dozens of organization policies and you can also create custom organization policies to meet granular requirements from your security department.
Logging and monitoring
Logging provides important functionality to development, auditing, and security, as well as helping to satisfy regulatory compliance. As shown in the following diagram, there are many use cases that can be leveraged on top of the collected logs:
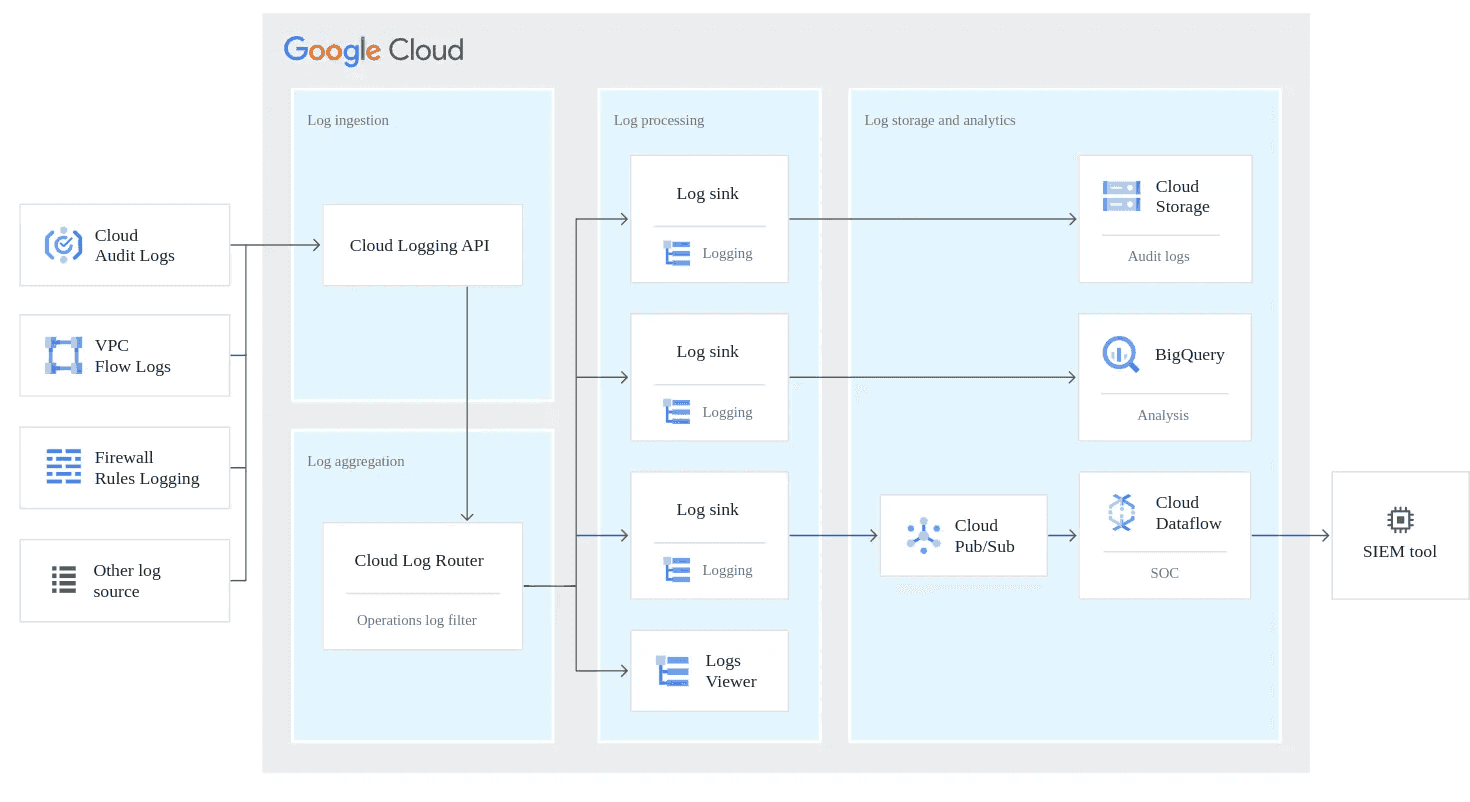
A lot can be written about how logging in Google Cloud and we have done so in this article that will give you the nitty-gritty details about the different levels of logging in Google Cloud.
In terms of logging related to data, you will want to create an organization sink for all your BigQuery logs. This will allow you to investigate all actions and activity done in BigQuery. It’s also recommended to develop a monitoring data product that leverages those logs to create datamarts that are then plugged into BI dashboards to gain various kinds of insights.
In terms of general security, a good practice is enabling all data access logs and creating a sink at the organization level that exports all those logs to a BigQuery dataset. This BigQuery dataset should be located on the dedicated logging project with restricted access. Tables within this dataset will contain all the data access audit logs and with those logs you can detect any kind of suspicious behaviors in your organisation. The monitoring data product can be used with those data logs in order to build datamarts with great security insights such as:
Abnormal amount of data movement out of the cloud
Denied access to a sensitive dataset from an identity
Alert on VPC Flow Logs being disabled
etc.
Google Security Command Center
The Security Command Center is Google Cloud’s unified security and risk-management dashboard — a true “single-pane-of-glass” for your entire Google Cloud estate. Its core components include:
Security Health Analytics
Continuously evaluate your configurations against Google-managed benchmarks (CIS, PCI, GDPR, and more) and surface misconfigurations as prioritized findings.Event Threat Detection (requires Premium)
Analyze VPC flow logs, DNS logs, and Cloud Audit Logs in real time to detect suspicious behaviors such as crypto-mining or data exfiltration.Findings & Investigation
Aggregate findings from SCC, Chronicle, Cloud IDS, and third-party feeds into a single inventory. Drill down into detailed alerts, context, and remediation guidance without switching tools.Integration & Automation
Export findings via Pub/Sub, Cloud Functions, or workflows to automate ticket creation, notify security teams, or even trigger automated remediation playbooks.Compliance: check your organization’s adherence to industry standards and certifications (e.g., ISO 27001, PCI DSS, FedRAMP). It provides a consolidated compliance score and detailed posture reports.
Assured Workloads: Enforce strict controls on your Google CLoud folders and projects to meet regulatory requirements. Assured Workloads applies organization-defined constraints — such as regional restrictions, prohibited services, and enforced encryption — so that workloads automatically comply with frameworks like HIPAA or CJIS.
By centralizing discovery, vulnerability scanning, threat detection, and compliance monitoring, SCC gives you end-to-end visibility and control over your Google Cloud security posture — no stitching together separate consoles or manual reports required.
Conclusion
If you have read until here, congratulations as this article was pretty long but it actually only scratches the surface regarding implementing robust and secured foundations for your data ecosystem on Google Cloud. Setting those foundations right is a daunting task due to the many variables and solutions at hand. Those foundations will also depend on your company’s needs and specificities, so there is definitely not a one-fit-all solution.
Whatever your plan regarding those foundations, what matters is that you have a plan and set those foundations before starting any analytics endeavors like BI, ML, etc. Having weak foundations will hinder your progress and your security. It will make, at best, data initiatives fail and, at worst, will generate data leakage that can lead to serious legal issues. While those foundations may seem like a costly burden, they will pay off significantly in the delivery of all your data initiatives subsequently.
Last but certainly not least, we have worked with many customers over the years setting up infrastructure and security foundations. While building a rigid solution is not feasible, we have come up with an accelerator that allows us to bootstrap those foundations with a lot of flexibility. Without prior knowledge, it may take you weeks/months to build strong foundations with potential issues. With our accelerator, we get things running in a matter of days and with the specificity required by your company.
Thank you
If you enjoyed reading this article, stay tuned as we regularly publish technical articles on data and Google Cloud. Follow Astrafy on LinkedIn, Medium and Youtube to be notified of the next article.
If you are looking for support on Modern Data Stack or Google Cloud solutions, feel free to reach out to us at sales@astrafy.io.
Written by

Charles Verleyen
CEO & Lead Architect



